|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
ГЛАВА 8Производительность и управление памятью
Определение модели памяти для приложенияСогласно приведенному выше суждению автора рассказов о Шерлоке Холмсе, необходимо различать ресурсы, которые должны быть всегда под рукой, и ресурсы, которые лучше всего переместить в долговременное хранилище. Применительно к мобильным устройствам это означает, что вы должны хорошенько подумать над тем, какую модель памяти следует использовать. Самое важное, что можно сказать о модели памяти, — это то, что она должна у вас быть. Было бы слишком легкомысленно допустить, чтобы в процессе разработки приложения разрастались сами по себе неконтролируемым образом, а не в соответствии с предварительно составленным планом. В случае приложений для настольных компьютеров это часто приводит к малопонятному коду, который трудно сопровождать и обновлять, и приложениям, которые функционируют не столь надежно и эффективно, как следовало бы. В случае мобильных приложений использование "сырой" модели памяти приводит к приложениям, которые обязательно упираются в "стену производительности", в результате чего они никогда не смогут функционировать так, как надо. В подобных ситуациях обычно трудно устранить проблемы, не прибегая к широкомасштабной переделке проекта. Разработка хорошо продуманной модели памяти позволяет избежать этой трясины и сделать проект более гибким. Целесообразно рассматривать использование памяти приложения на двух различных уровнях: 1. Управление памятью на макроскопическом "уровне приложения". Этот уровень относится к данным и ресурсам уровня приложения, которые поддерживаются вашим приложением в процессе выполнения. Эти данные обычно существуют в течение длительного времени, и их область видимости не ограничивается пределами отдельных функций. Для создания эффективно функционирующего мобильного приложения очень важно иметь надежную модель, управляющую объемом данных, подлежащих хранению в памяти в каждый момент времени, и удалением из памяти данных и ресурсов, непосредственное использование которых в ближайшее время не ожидается. Чрезмерный объем долгоживущих данных состояния загромождает память, которую можно было бы использовать для кэширования JIT-компилированного кода или как рабочую память для функций, и заставляет многократно и не самым эффективным образом очищать память от "мусора". 2. Распределение памяти на микроскопическом "уровне алгоритма". Временную память для выполнения команд, определяемых вашими алгоритмами, распределяют функции. Эффективность этого процесса зависит от вашей стратегии реализации алгоритмов. Например, при написании кода, который должен выполняться в циклах, необходимо как можно тщательнее продумывать его эффективность в отношении использования ресурсов, чтобы свести к минимуму непроизводительные накладные расходы. Уделяя пристальное внимание эффективности распределения памяти в создаваемых вами алгоритмах, вы сможете значительно повысить общую производительность приложения. Приложения для настольных компьютеров, хранящие в памяти большие рабочие наборы (рабочий набор, равный всей используемой памяти), обычно выталкивают в дисковый файл подкачки все новые и новые данные. Это позволяет освобождать память от редко используемых данных, что несколько сглаживает отрицательные последствия неэкономного управления памятью на макроскопическом уровне приложения. Результирующее поведение производительности в зависимости от объема используемой памяти в широких пределах носит примерно линейный характер. Кроме того, среды выполнения управляемого кода на настольных компьютерах располагают сложными механизмами очистки памяти от неиспользуемых объектов, что может частично нивелировать недостатки расточительных в отношении использования памяти алгоритмов. Это способствует повышению производительности приложения на микроскопическом уровне. Неэффективное управление памятью имеет отрицательные последствия и в случае приложений, выполняющихся на настольных компьютерах, однако огромная емкость вычислительной среды сглаживает эти эффекты. ОЗУ мобильных устройств имеют гораздо меньший объем и, как правило, не позволяют надлежащим образом реализовать механизмы, использующие дополнительные внешние накопители для организации быстрого обмена страницами с памятью. Кроме того, в условиях ограниченных ресурсных возможностей на мобильных устройствах могут быть реализованы лишь сравнительно простые механизмы очистки памяти от неиспользуемых объектов. Это означает, что небрежно организованное управление памятью в приложениях для мобильных устройств будет иметь весьма заметные отрицательные последствия как на макроскопическом, так и на микроскопическом уровнях. По сравнению с настольными компьютерами мобильные устройства гораздо менее терпимы к любым просчетам в управлении памятью. Использование тщательно продуманного управления памятью обеспечивает значительные преимущества как при разработке приложений для настольных компьютеров, так и при разработке приложений для мобильных устройств, однако в последнем случае такой подход должен быть обязательно плановым. Отсутствие продуманного управления памятью в случае приложений для настольных компьютеров приводит к постепенному обрастанию приложения неиспользуемыми объектами и замедлению его работы. В противоположность этому мобильное приложение, работающее без применения выверенных стратегий управления памятью на макроскопическом и микроскопическом уровнях, очень быстро пересекает опасную черту, и его дальнейшее использование становится истинным мучением. Управление памятью на макроскопическом "уровне приложения"На рис. 8.1 в схематическом виде отображено, как снижается производительность приложения с увеличением объема используемой памяти. 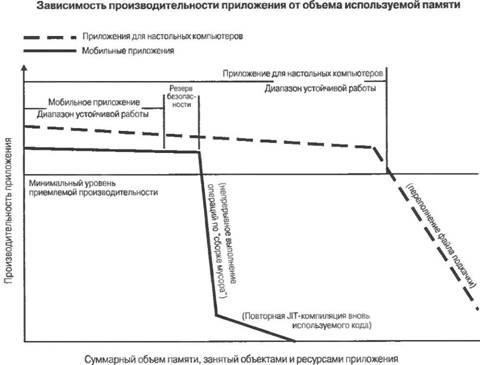 Рис. 8.1. Изменение производительности приложения с увеличением объема используемой памяти Из поведения графиков видно, что в случае приложений для настольных компьютеров диапазон объемов используемой памяти, при которых производительность остается в допустимых пределах, является намного более широким. При превышении некоторого порогового значения производительность резко снижается, поскольку начинается свопинг данных между памятью и файлом подкачки, а сборщик мусора все чаще пытается освобождать и уплотнять память; вместе с тем, падение производительности происходит гораздо медленнее, чем в случае мобильных устройств. Для мобильных устройств диапазон используемых объемов памяти, при которых производительность остается на приемлемом уровне, оказывается более узким. При превышении некоторого порогового значения наблюдается резкое падение производительности мобильного приложения, поскольку сборщик мусора работает почти непрерывно, пытаясь высвободить все большие объемы памяти. На графиках отмечены участки, соответствующие использованию объемов памяти, при которых приложение еще способно нормально функционировать. Коль скоро потребление памяти не превышает некоторого критического значения, ничего особенного в целом не происходит. Однако при пересечении критической точки производительность приложения резко падает, поскольку сборщик мусора вынужден работать все чаще, изо всех сил пытаясь высвободить память для нужд приложения. Будут ли меня преследовать те же проблемы, если я пишу приложение на основе собственного кода? Перед вами, как перед проектировщиком мобильного приложения, не стоит задача найти способы, позволяющие использовать всю свободную память вплоть до некоторой пороговой величины, при превышении которой производительность начинает резко ухудшаться. Вместо этого вы должны стремиться к тому, чтобы у вас всегда оставался некоторый резервный запас свободной памяти (резерв безопасности), оставляющий простор для маневров, что будет гарантией эффективного выполнения вашего приложения в самых различных ситуациях. Необходимость такого подхода диктуется тем, что в типичных условиях ваше приложение не имеет возможности полностью контролировать всю установленную на устройстве память; память находится в совместном распоряжении операционной системы и всех приложений, которые могут одновременно выполняться пользователем. Если какое-то приложение распределяет и удерживает лишние объемы памяти, то от этого будет страдать производительность всех приложений. Не занимайте больше памяти, нежели требуется, и освобождайте те ее излишки, непосредственная необходимость в которых отпала Как и в случае других аспектов проектирования мобильных приложений, разработка удачной модели памяти, удовлетворяющей всем вашим требованиям, возможна лишь в результате проведения экспериментов и при наличии опыта. Вы должны экспериментально проверить самые различные подходы, и довести характеристики модели до нужных, исходя из доступных ресурсов мобильного устройства и требований приложения. Залогом успешной разработки мобильных приложений является творческий подход к решению проблем, открывающий широкий простор для экспериментов. Не решатся ли обсуждаемые проблемы сами по себе с приходом мобильных устройств "следующего поколения"? Хранить в памяти неиспользуемые объекты слишком расточительно, поскольку они занимают место, которое можно было бы использовать с большей эффективностью для активных составляющих вашего приложения. С другой стороны, было бы слишком легкомысленно освобождать память от объектов сразу же после того, как непосредственная необходимость в них исчезла. Обратимся к метафоре. Предположим, что вы живете в небольшой квартире и для скрепления бумажных листов вам потребовался скоросшиватель, который вы должны купить, сходив для этого в магазин. Это займет у вас время и ресурсы — не очень много, но вполне достаточно, чтобы вы это ощутили. Выбросив скоросшиватель сразу же после того, как он будет использован, вы освободите в квартире немного места (фактически это произойдет лишь после того, как вы избавитесь от мусора в ведре, в которое выбросили скоросшиватель), но останетесь без скоросшивателя. Если впоследствии вам вновь понадобится что-либо скрепить, вы должны будете опять потратить время на посещение магазина и понести расходы, покупая новый скоросшиватель. Если бы все происходило именно так, то ваши действия следовало бы рассматривать как опрометчивые; зная, что на протяжении ближайшего года-двух скоросшиватель вам вновь может понадобиться, его лучше было бы держать где-то поблизости. Однако если вы абсолютно уверены в том, что необходимость в скоросшивателе повторно никогда не возникнет (возможно, с этого момента вы решили пользоваться только зажимами), то вы должны выбросить его, как бы мало места он ни занимал. Кому охота загромождать квартиру бесполезными вещами? Во всем должен существовать определенный баланс, который вам предстоит определить. Поскольку скоросшиватель — вещь довольно полезная, по своим размерам не очень габаритная и время от времени может использоваться, то его следует оставить под рукой. А что можно сказать по поводу большого парового пылесоса для чистки ковров? Опять-таки, вы могли бы сходить в магазин, купить пылесос, затратив на это значительные денежные и временные ресурсы, и держать его где-то в квартире; в то же время, если вы живете в небольшой квартирке и чистите свои ковры сравнительно редко, то такое решение было бы не самым разумным. Вместо этого вам следовало бы взять пылесос напрокат, сделать все, что надо, а затем отнести его обратно в пункт проката. Вы всегда должны планировать, какие вещи лучше держать при себе, а от каких лучше избавляться, когда они сделали свое дело. Сложнее всего принимать решения относительно объектов, которые попадают в промежуточную категорию. Сами по себе эти объекты не отличаются большими размерами или высокой стоимостью, каждый из них занимает сравнительно немного места и они могут оказаться потенциально полезными в не столь отдаленном будущем. Эти объекты можно уподобить одежде, которую вы почти никогда не носите. Ее можно было бы и выбросить, но также неплохо оставить у себя на тот случай, если вы измените свое мнение. Если такие объекты немногочисленны, то держать их поблизости не составляет труда, но в эту категорию попадает так много объектов, что легко заполнить ими все имеющиеся помещения, что не оставит вам места для тех вещей, которыми вы пользуетесь наиболее часто. Может так оказаться, что вся ваша квартира будет забита одеждой, которую вы редко носите, и ящиками с барахлом, которое вы почти никогда не используете. Если у вас громадный дом с множеством помещений, то ничего ужасного в этом нет, но если вы живете в квартире, то она окажется забитой вещами до потолка. Настольный компьютер — суть "большой дом". Мобильное устройство — суть "квартира". Очевидно, что должны существовать какие-то правила, регламентирующие, что следует держать под рукой, а от чего необходимо избавляться. Действительно, такие правила существуют но, к счастью, они основываются на здравом смысле, и главное заключается в том, чтобы их систематически применять. Именно в том и состоит на значение явной модели использования памяти приложения, чтобы гарантировать последовательное применение основанных на здравом смысле соображений, обеспечивающих эффективное выполнение мобильного приложения. Как и все другие проблемы технического характера, эта проблема также должна решаться на основе достижения определенного компромисса. Нежелание отказываться от хранения объектов, необходимость в которых впоследствии вновь может возникнуть, должно сопоставляться с теми преимуществами в отношении производительности приложения, которые обеспечиваются наличием свободной памяти. Информация какого типа должна охватываться вашей макромоделью памяти? Полезно рассортировать данные и ресурсы приложения, с которыми вы работаете, на две разновидности: 1) объекты и ресурсы, которые необходимы приложению для эффективного выполнения, и 2) фактическая пользовательская информация, с которой работает приложение. 1. Необходимые служебные данные приложения. В эту разновидность входят ресурсы, необходимые приложению для поддержания пользовательского интерфейса и других аспектов выполнения приложения. В качестве примера можно привести открытые соединения с базами данных, открытые файлы, потоки выполнения, графические объекты, а также такие объекты пользовательского интерфейса, как кисти, перья, элементы управления форм и формы как таковые. Все эти объекты не имеют непосредственного отношения к данным, с которыми фактически работает пользователь, но жизненно необходимы для фактического взаимодействия приложения с пользователем или с внешними источниками информации. 2. Пользовательские данные. К этой разновидности относятся фактические данные, в работе с которыми заинтересован пользователь. Под этими данными подразумевается та часть данных, которая удерживается в памяти, а не хранится в базе данных или файле на устройстве или вне его. Например, если мобильное приложение предназначено для того, чтобы облегчить пользователю проезд по улицам Лондона, то пользовательскими данными является информация о расположении улиц, которая в данный момент загружена в память. Если приложение предназначено для ведения инвентарного учета, то пользовательскими данными являются загруженные инвентаризационные данные. Если приложение представляет собой игру в шахматы, то пользовательскими данными является представление состояния шахматной доски в памяти машины. И здесь вам вновь могут пригодиться конечные автоматы. Предусмотрите для своего приложения два высокоуровневых конечных автомата, каждый из которых предназначен для управления одной из двух вышеупомянутых разновидностей данных. Служебные данные приложения и пользовательские данные целесообразно разделить и предусмотреть для управления каждой из этих разновидностей данных свой конечный автомат. Являются ли растровые изображения "пользовательскими" данными или "служебными" данными приложения? Управление "служебными" данными приложенияКак ранее уже отмечалось, "служебные" данные приложения — это те данные, с которыми пользователь непосредственно не взаимодействует и которые, таким образом, не являются "пользовательскими" данными. Эти данные представляют собой ресурсы, необходимые для эффективного функционирования приложения, а также отображения данных и манипулирования ими. Управление объектами и ресурсами, необходимыми для того, чтобы приложение могло эффективно выполняться, обычно может осуществляться с помощью простого конечного автомата. По мере прохождения приложением различных состояний ресурсы, которые полезно иметь под рукой, могут меняться. При переходе в новое состояние необходимые ресурсы могут создаваться и сохраняться в памяти приложения. Аналогичным образом, если приложение покидает некоторое состояние, то ресурсы, которые в новом состоянии непосредственно не требуются, могут быть удалены из памяти, а освобожденная память возвращена в пул свободной памяти. Часто эти состояния соответствуют отображаемым в данный момент формам или их вкладкам, которые пользователь имеет возможность листать, поочередно вызывая их на передний план. Во многих случаях при проектировании модели состояний приложения полезно идентифицировать дискретный ряд возможных режимов работы пользовательского интерфейса и применять их в качестве основы для построения модели состояний. Рассмотрим в качестве примера простое приложение, ориентированное на работу с базами данных. Данное приложение обеспечивает хранение и обработку медицинских данных пациентов. Данные хранятся в базе данных и загружаются порциями, которые соответствуют отдельным пациентам, причем для загрузки или сохранения данных о пациенте требуется ввести защитный пароль. Для приложений такого рода можно выделить пять различных дискретных состояний, в которых пользователю для выполнения соответствующих задач предоставляются различные пользовательские интерфейсы. Такими состояниями являются следующими: 1. Загрузка данных из базы данных. Этот экран предоставляет пользователю возможность подтвердить свои права доступа к базе данных и загрузить данные конкретного пациента. К необходимым служебным данным приложения относятся следующие данные: • Соединения с базой данных. • Форма, отображающая пользовательский интерфейс, необходимый для входа в базу данных. 2. Сохранение данных в базе данных. Этот экран предоставляет пользователю возможность подтвердить свои права доступа к базе данных и сохранить данные конкретного пациента. К необходимым служебным данным приложения относятся следующие данные. • Соединения с базой данных. • Форма, отображающая пользовательский интерфейс, необходимый для входа в базу данных. 3. Основной экран приложения. Этот экран отображает данные истории болезни пациента, которые были загружены из базы данных, и предоставляет пользователю устройства возможность просматривать данные и переходить от одних данных к другим. К необходимым служебным данным приложения относятся следующие данные: • Форма для основного экрана. • Изображения общего назначения, используемые в пользовательском интерфейсе. 4. Экран, отображающий подробную информацию, необходимую для работы с конкретными данными и их редактирования. Этот экран отображается тогда, когда пользователю необходимо редактировать отдельные элементы данных о пациенте или вводить новые данные. К необходимым служебным данным приложения относятся следующие данные: • Форма для редактирования загруженной записи. • Пользовательские элементы управления формы, обеспечивающие нестандартные возможности ввода данных (например, пользовательский элемент управления для ввода данных о кровяном давлении с одновременной проверкой корректности ввода или пользовательский элемент управления для редактирования информации о медикаментозных дозах). 5. Экран диаграмм для отображения наборов точек, соответствующих данным. Этот экран предназначается для отображения графической информации, связанной с некоторыми аспектами истории болезни пациента. Например, могут быть построены диаграммы, представляющие изменение кровяного давления или количество белых кровяных телец с течением времени, по которым можно судить о наличии инфекции. К необходимым служебным данным приложения относятся следующие данные: • Графические перья и кисти, используемые для рисования диаграмм. • Объекты шрифтов, используемых для отображения надписей на диаграммах. • Кэшированные фоновые изображения. • Внеэкранная поверхность растрового изображения, используемая для подготовки изображения диаграммы перед его копированием на экран. Некоторые из этих состояний разделяют общие ресурсы. Например, графическое перо черного цвета, или шрифт определенного размера, или растровое изображение могут использоваться в нескольких из перечисленных выше состояний. В соединении с базой данных нуждаются два состояния. Кроме того, некоторые объекты могут не требоваться для всех без исключения состояний, но их создание занимает длительное время; в этом случае целесообразно прибегнуть к кэшированию объектов, которое предварительно следует протестировать с точки зрения влияния на производительность. Создать конечный автомат для управления этими видами ресурсов не составляет особого труда. Все, что требуется сделать при вхождении в новое состояние — это определить, какие объекты необходимо создать, если они к этому времени еще не существуют, и какие из размещенных в предыдущем cocтоянии объектов должны быть удалены из памяти. Управление этой логикой с помощью всего лишь одного конечного автомата, а не посредством кода, разбросанного по всему приложению, позволяет легко поддерживать данную информацию. Кроме того, конечный автомат облегчает проведение экспериментов с различными схемами оптимизации и настройку производительности приложения. Использование интерфейса IDisposable и освобождение дорогостоящих неуправляемых ресурсов в .NET Compact Framework Управление объемом пользовательских данных, хранящихся в памятиПользовательские данные представляют собой фактические данные, которые может просматривать или которыми может манипулировать пользователь приложения. Управление объемом и временем жизни пользовательских данных, хранящихся в памяти, может оказаться более сложным по сравнению с управлением служебными данными приложения, поскольку в зависимости от структуры и назначения приложения природа данных, сохраняемых в памяти, может быть самой различной. Пользовательские данные шахматной игры отличаются своей структурой от пользовательских данных истории болезни пациента. Состояние шахматной доски может храниться в целочисленном массиве фиксированных размеров. Объем данных истории болезни не может быть заранее определен; эти данные могут включать в себя результаты измерений, текстовые записи, изображения, ссылки на дополнительные данные и почти неограниченный объем любой другой подходящей информации. Управление состоянием шахматной доски обычно сводится к принятию решений относительно того, когда именно следует загружать массив данных в память, сохранять его и удалять из памяти. С этим можно справиться при помощи конечного автомата, предназначенного для решения этой задачи. Управление памятью, используемой для хранения сложных записей истории болезни пациента, выглядит значительно сложнее. Указанные записи могут иметь произвольный размер, а это, вероятно, означает, что вам придется прибегнуть для работы с ними к оконной модели, в которой пользователь устройства обеспечивается частичным представлением набора данных, причем не все данные должны храниться в памяти одновременно. У пользователя создается впечатление, что в памяти находятся все данные, тогда как на самом деле осуществляется подкачка необходимых данных. Соответствующий конечный автомат может быть как очень простым, так и необычайно сложным, в зависимости от того, что собой представляют управляемые данные, и какие ресурсы доступны для управления этими данными. Для управления потенциально сложными пользовательскими данными целесообразно использовать подход, предполагающий создание класса с хорошо продуманной инкапсуляцией, который и реализует управление состоянием, хранящимся в памяти в каждый момент времени. Этот класс отвечает за загрузку новых данных и освобождение памяти от старых данных, когда необходимость в них отпадает. Он управляет доступом к пользовательским данным извне и создает иллюзию неограниченных запасов памяти. Любой другой код приложения, осуществляющий доступ к данным извне инкапсулирующего класса, ничего не должен знать о внутреннем состоянии этого класса, реализующего фактическое управление пользовательскими данными. Возложение ответственности за управление всеми пользовательскими данными на определенный класс обеспечивает значительную гибкость в процессе проектирования. Некоторые из преимуществ такого подхода перечисляются ниже: ■ Возможность автоматического управления объемом загруженных данных. Если вы обнаруживаете, что приложение испытывает острый дефицит памяти, можно уменьшить размеры окна данных, удерживаемых в памяти в каждый момент времени, не прибегая к внесению изменений в пределах всего приложения. Поскольку о том, какие данные кэшированы в памяти, а какие нуждаются в повторной загрузке, вне данного класса ничего не известно, вы получаете более гибкие возможности для настройки этого алгоритма. ■ Возможность иметь различные реализации для различных классов устройств. Если ваши целевые устройства охватывают несколько различных классов, то вы имеете возможность настроить ограничения на использование памяти и накопителей для каждого из этих классов по отдельности. Мобильный телефон и устройство PDA могут иметь различные характеристики памяти и различные возможности в отношении загрузки данных по требованию. Отмеченные различия могут потребовать от вас использования различных подходов к кэшированию данных. Концентрация соответствующей управляющей логики в одном месте существенно упрощает эту задачу. Использование модели загрузки данных по требованиюДля размещения объектов в памяти существуют две стратегии: 1. При вхождении приложения в новое состояние создаются все объекты, которые требуются для этого состояния. Достоинством этой стратегии является ее простота. Когда приложение переходит в новое состояние, вы просто вызываете функцию, которая и обеспечивает доступность и возможность использования всех необходимых объектов. Эта стратегия очень хорошо работает в тех случаях, когда имеется уверенность в том, что в ближайшее время приложению потребуются все созданные объекты. Возможные проблемы связаны с тем, что если ваше приложение находится в стадии становления и в его проект могут вноситься изменения, то применение указанной стратегии может привести к хранению в памяти большого количества ненужных объектов. Поскольку старые объекты, необходимости в которых больше нет, все равно создаются и загружаются в память, то драгоценные ресурсы тратятся понапрасну. Будьте внимательны при групповом создании наборов объектов, ибо в процессе выполнения вашего приложения может наступить такой момент, когда создаваемые объекты не используются, но связанные с ними накладные расходы ухудшают производительность. 2. Создание любого объекта откладывается до тех пор, пока необходимость в его создании не станет очевидной. Эта модель немного сложнее в проектировании, но зато во многих случаях оказывается более эффективной, поскольку объекты создаются лишь тогда, когда в них возникает действительная необходимость. При обсуждении этой модели часто употребляются такие выражения, как "фабрика классов" ("class factory"), "диспетчер ресурсов" ("resource dispenser") и "отложенная загрузка" ("lazy loading"). Приведенный в листинге 8.1 пример кода иллюстрирует два способа отложенного создания и кэширования глобально используемых графических ресурсов. Существует два способа создания объектов: 1. Пакетное создание групповых ресурсов. Приведенный ниже код создает списочный массив, содержащий четыре растровых изображения. Эти изображения являются кадрами анимации, поэтому они загружаются все вместе и помещаются в индексированный массив, откуда их можно легко извлекать. Программный код, которому требуется доступ к этой коллекции изображений, должен использовать вызов GraphicsGlobals.PlayerBitmapsCollection();. Если массив изображений уже загружен в память, функция незамедлительно возвращает кэшированный объект. В противном случае отдельные ресурсы изображений сначала загружаются в массив и лишь затем возвращаются. Если приложение переходит в состояние, в котором пребывание изображений в памяти не требуются, код приложения может выполнить вызов GraphicsGlobals.g_PlayerBitmapsCollection_CleanUp();, в результате чего произойдет освобождение растровых ресурсов и массива. Системные ресурсы, задействованные для обслуживания растровых изображений, будут немедленно освобождены, а управляемая память, которую занимали эти объекты, будет соответствующим образом восстановлена в процессе сборки мусора. 2. Индивидуальное создание графических ресурсов. В случае ресурсов, которые не должны обязательно использоваться вместе, как в приведенном выше примере, часто оказывается удобным создать функцию кэшированного доступа, посредством которой и реализуется управление доступом к ресурсу. Когда происходит первое обращение к этой функции с запросом ресурса (например, GraphicsGlobals.g_GetBlackPen();), она создает его экземпляр. В случае часто используемых ресурсов такой подход оказывается намного более эффективным, чем постоянное создание и уничтожение экземпляров ресурса всякий раз, когда он требуется для выполнения того или иного фрагмента кода. Создавая приведенный ниже код, я допустил, что все ресурсы должны освобождаться одновременно, и написал функцию (GraphicsGlobals.g_CleanUpDrawingResources();), которая освобождает все кэшированные ресурсы, которые были созданы. Эта функция должна вызываться тогда, когда приложение переходит в состояние, в котором эти ресурсы не требуются. Используя кэширование, руководствуйтесь здравым смысломЛистинг 8.1. Применение отложенной загрузки, кэширования и освобождения графических ресурсов using system; public class GraphicsGlobals { private static System.Drawing.Bitmap s_Player_Bitmap1; private static System.Drawing.Bitmap s_Player_Bitmap2; private static System.Drawing.Bitmap s_Player_Bitmap3; private static System.Drawing.Bitmap s_Player_Bitmap4; private static System.Collections.ArrayList s_colPlayerBitmaps; //------------------------------------------------------ //Освободить все ресурсы //------------------------------------------------------ public static void g_PlayerBitmapsCollection_CleanUp() { //Если не загружено ни одно изображение, то и память освобождать не от чего if (s_colPlayerBitmaps == null) { return; } //Дать указание каждому из этих объектов освободить //любые удерживаемые ими неуправляемые ресурсы s_Player_Bitmap1.Dispose(); s_Player_Bitmap2.Dispose(); s_Player_Bitmap3.Dispose(); s_Player_Bitmap4.Dispose(); //Обнулить каждую из этих переменных, чтобы им не соответствовали //никакие объекты в памяти s_Player_Bitmap1 = null; s_Player_Bitmap2 = null; s_Player_Bitmap3 = null; s_Player_Bitmap4 = null; //Избавиться от массива s_colPlayerBitmaps = null; } //Функция: возвращает коллекцию изображений public static System.Collections.ArrayList g_PlayerBitmapsCollection() { //--------------------------------------------------------------- //Если изображения уже загружены, их достаточно только возвратить //--------------------------------------------------------------- if (s_colPlayerBitmaps != null) { return s_colPlayerBitmaps; } //Загрузить изображения как ресурсы из исполняемого двоичного файла System.Reflection.Assembly thisAssembly = System.Reflection.Assembly.GetExecutingAssembly(); System.Reflection.AssemblyName thisAssemblyName = thisAssembly.GetName(); string assemblyName = thisAssemblyName.Name; //Загрузить изображения s_Player_Bitmap1 = new System.Drawing.Bitmap( thisAssembly.GetManifestResourceStream(assemblyName + ".Hank_RightRun1.bmp")); s_Player_Bitmap2 = new System.Drawing.Bitmap( thisAssembly.GetManifestResourceStream(assemblyName + ".Hank RightRun2.bmp")); s_Player_Bitmap3 = new System.Drawing.Bitmap( thisAssembly.GetManifestResourceStream(assemblyName + ".Hank_LeftRun1.bmp")); s_Player_Bitmap4 = new System.Drawing.Bitmap( thisAssembly.GetManifestResourceStream(assemblyName + ".Hank_LeftRun2.bmp")); //Добавить изображения в коллекцию s_colPlayerBitmaps = new System.Collections.ArrayList(); s_colPlayerBitmaps.Add(s_Player_Bitmap1); s_colPlayerBitmaps.Add(s_Player_Bitmap2); s_colPlayerBitmaps.Add(s_Player_Bitmap3); s_colPlayerBitmaps.Add(s_Player_Bitmap4); //Возвратить коллекцию return s_colPlayerBitmaps; } private static System.Drawing.Pen s_blackPen; private static System.Drawing.Pen s_whitePen; private static System.Drawing.Imaging.ImageAttributes s_ImageAttribute; private static System.Drawing.Font s_boldFont; //------------------------------------------------ //Вызывается для освобождения от любых графических //ресурсов, которые могли быть кэшированы //------------------------------------------------ private static void g_CleanUpDrawingResources() { //Освободить память от черного пера, если таковое имеется if (s_blackPen !=null) { s_blackPen.Dispose(); s_blackPen = null; } // Освободить память от белого пера, если таковое имеется if (s_whitePen != null) { s_whitePen.Dispose(); r_whitePen = null; } //Освободить память от атрибута ImageAttribute, если таковой имеется. //Примечание. Метод Dispose() для этого типа не предусмотрен, //поскольку все его данные являются управляемыми if (s_ImageAttribute != null) { s_ImageAttribute = null; } //Освободить память от полужирного шрифта, если таковой имеется if (s_boldFont != null) { s_boldFont.Dispose(); s_boldFont = null; } } //----------------------------------------- //Эта функция позволяет получить доступ //к черному перу, находящемуся в кэш-памяти //----------------------------------------- private static System.Drawing.Pen g_GetBlackPen() { //Если перо еще не существует, создать его if (s_blackPen ==null) { s_blackPen = new System.Drawing.Pen(System.Drawing.Color.Black); } //Возвратить черное перо return s_blackPen; } //---------------------------------------- //Эта функция позволяет получить доступ //к белому перу, находящемуся в кэш-памяти //---------------------------------------- private static System.Drawing.Pen g_GetWhitePen() { //Если перо еще не существует, создать его if (s_whitePen == null) { s_whitePen = new System.Drawing.Pen(System.Drawing.Color.White); } //Возвратить белое перо return s_whitePen; } //----------------------------------------------- //Эта функция позволяет получить доступ //к полужирному шрифту, находящемуся в кэш-памяти //----------------------------------------------- private static System.Drawing.Font g_GetBoldFont() { //Если перо еще не существует, создать его if (s_boldFont ==null) { s_boldFont = new System.Drawing.Font( System.Drawing.FontFamily.GenericSerif, 10, System.Drawing.FontStyle.Bold); } //Возвратить полужирный шрифт return s_boldFont; } //------------------------------------------------------ //Эта функция позволяет осуществлять доступ //к находящемуся в кэш-памяти объекту imageAttributes, // который мы используем для изображений с прозрачностью //------------------------------------------------------ private static System.Drawing.Imaging.ImageAttributes g_GetTransparencyImageAttribute() { //Если объект не существует, создать его if (s_ImageAttribute == null) { //Создать атрибут изображения s_ImageAttribute = new System.Drawing.Imaging.ImageAttributes(); s_ImageAttribute.SetColorKey(System.Drawing.Color.White, System.Drawing.Color.White); } //Возвратить его return s_ImageAttribute; } } //Конец класса Управление памятью на микроскопическом "уровне алгоритма"Современные языки программирования, библиотеки классов и управляемые среды времени выполнения позволили значительно повысить продуктивность написания программ. В то же время, избавляя программиста от необходимости задумываться о низкоуровневом распределении памяти, в котором нуждаются алгоритмы, они невольно создают предпосылки для написания неэффективного кода. Неэффективность кода может быть обусловлена причинами двоякого рода: 1. Вычислительная неэффективность алгоритма. Этот вид неэффективности наблюдается в тех случаях, когда спроектированный вами алгоритм предусматривает интенсивные вычисления или выполнение большего количества циклов, чем это объективно необходимо, от чего можно было бы избавиться, используя более эффективные алгоритмы. В качестве классического примера можно привести сортировку массива данных. Иногда у вас может появляться возможность выбирать между несколькими возможными вариантами алгоритмов сортировки, отдельными частными случаями которых могут, например, быть алгоритмы "порядка N" (линейная зависимость времени вычислений от количества сортируемых элементов), "порядка N*Log(N)" (зависимость времени вычислений от количества сортируемых элементов отличается от линейной, но остается все же лучшей, чем экспоненциальная) или "порядка N^2" (экспоненциальная зависимость времени вычислений от количества сортируемых элементов). Кроме вышеперечисленных "порядков" возможно множество других (например, N^3). Выбор наиболее подходящего алгоритма зависит от объема данных, с которыми вы работаете, объема доступной памяти и ряда других факторов, например, от состояния рабочих данных. Отдельные стратегии, например, предварительная обработка данных перед отправкой их на устройство или хранение данных в формате, специфическом для использования памяти в качестве хранилища, способны обеспечить значительное повышение производительности алгоритма. Существует огромное количество компьютерной литературы, посвященной проектированию эффективных алгоритмов и оценке их быстродействия, поэтому никаких попыток более подробного анализа этих вопросов в данной книге не делается. Необходимо только отметить, что чем больше объем обрабатываемых данных, тем ответственнее необходимо отнестись к принятию решения относительно выбора вычислительного алгоритма. Во всех затруднительных случаях тщательно анализируйте алгоритм и обращайтесь к существующей литературе по этому вопросу. Очень часто оказывается так, что кто-то другой уже прошел этот путь, и вам остается лишь перенять их опыт. 2. Неэффективное распределение памяти. После того как вы определитесь со стратегией алгоритма, следующим фактором, от которого в значительной степени за висит производительность приложения, является способ реализации этого алгоритма. При этом едва ли не наибольшие усилия вы должны приложить к тому, чтобы избежать распределения лишних объемов памяти, особенно если память распределяется в циклах. В данном разделе этой книги основное внимание уделяется именно этому вопросу. Вашей целью должно быть распределение "нулевых объемов памяти" внутри циклов в написанном вами коде. Существуют случаи, когда это является неизбежным, как, например, при построении дерева объектов, которое требует размещения в памяти новых узлов для помещения их в иерархическую структуру. Во многих других случаях эффективность приложения можно существенно повысить, тщательно анализируя распределение памяти для каждого объекта и рассматривая альтернативные решения. Чего, как правило, следует избегать — так это выполнения операций размещения объектов в памяти и удаления их из памяти внутри алгоритмических циклов. Пишите аккуратные алгоритмы: не сорите!Как и в реальной жизни, сор в программировании — это отходы производственной деятельности, которые должны выбрасываться. Обычно сор появляется в результате неряшливости и неаккуратности. Стремление к получению кратковременных удобств часто порождает долговременные проблемы. При создании в алгоритмах мусора в виде временных объектов, необходимости в которых на самом деле нет, работа приложения замедляется в результате воздействия непосредственных и косвенных факторов: 1. Непосредственные факторы. Каждый раз, когда вы создаете объект, перед его использованием должна быть распределена и инициализирована память. Это прямые предварительные расходы, которые должен оплатить ваш алгоритм. 2. Косвенные факторы. После того как приложение освободило объект, он становится "мусором" Этот мусор накапливается в приложении, пока его не соберется так много, что для последующего распределения памяти для новых объектов потребуется ее предварительная очистка от старых. Конечно же, именно это и называется сборкой мусора. На сборку мусора уходит определенное время, и если мусора много, то эта операция заметно затормозит работу вашего приложения. Чем больше вы сорите, тем больше накапливается мусора и тем чаще приходится тратить время на уборку! В процессе программирования вы всегда должны стараться "сорить" как можно меньше. Нет ничего плохого в том, чтобы создать экземпляр объекта, если это помогает решить какую-то очень важную задачу; если же объект является короткоживущим и задача может быть решена без него, то вы только создаете мусор. Не будьте "неряхой"! "Структуры" и .NET Compact Framework Пишите экономные алгоритмы: разумно расходуйте память и повторно используйте объектыПредставленный ниже пример иллюстрирует несколько различных вариантов реализации одного и того же базового алгоритма. Алгоритм предназначен для обработки массива строк. Каждая строка в массиве состоит из трех частей, разделенных символом подчеркивания (например, big_shaggy_dog). Алгоритм предполагает просмотр каждого из элементов массива и проверку того, не является ли его средняя часть словом blue (например, my_blue_car). Если это так, то слово blue заменяется словом orange (например, my_blue_car становится my_orange_car). Кроме того, в каждом из описанных алгоритмов используется вспомогательный класс, упрощающий разбиение строк и получение данных, содержащихся в каждом из трех сегментов. Первый алгоритм (листинги 8.3 и 8.4) представляет собой некое разумное первое приближение, а следующие два алгоритма (листинги 8.5 и 8.6 и листинги 8.7 и 8.8) — его оптимизированные варианты, улучшающие первоначальную тактику. Целью оптимизации являлось непосредственное улучшение производительности, а также уменьшение количества "мусора", вырабатываемого каждым из алгоритмов. Листинг 8.2. Общий код, используемый во всех приведенных ниже вариантах тестов//Желаемое число повторений теста const int LOOP_SIZE = 8000; //--------------------------------------------------- //Эта функция переустанавливает содержимое нашего тестового //массива, что обеспечивает возможность многократного //выполнения тестового алгоритма //--------------------------------------------------- private void ResetTestArray(ref string[] testArray) { if (testArray == null) { testArray =new string[6]; } testArray[0] = "big_blue_duck"; testArray[1] = "small_yellow_horse"; testArray[2] = "wide_blue_cow"; testArray[3] = "tall_green_zepplin"; testArray[4] = "short_blue_train"; testArray[5] = "short_purple_dinosaur"; }Листинг 8.3. Тестовый пример, демонстрирующий неэкономное распределение памяти (типичный первоначальный вариант реализации интересующей нас функции) Примечание. В этом примере используется класс PerformanceSampling, определенный ранее в данной книге. private void button2_Click(object sender, System.EventArgs e) { //Вызвать сборщик мусора, чтобы быть уверенными в том, //что тест начнется с чистого состояния. //ПРИБЕГАЙТЕ К ЭТОЙ МЕРЕ ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ! Вызовы //сборщика мусора в программах вручную будут приводить к снижению //общей производительности приложений! System.GC.Collect(); string [] testArray = null; //-------------------------------------------- //Просмотреть элементы массива и найти //те из них, в которых средним словом является //"blue". Заменить "blue" на "orange" //-------------------------------------------- //Запустить секундомер для нашего теста! PerformanceSampling.StartSample(0, "WastefulWorkerClass"); WastefulWorkerClass workerClass1; int outerLoop; for (outerLoop = 0; outerLoop < LOOP_SIZE; outerLoop++) { //Присвоить элементам массива значения, которые мы хотим //использовать при тестировании ResetTestArray(ref testArray); int topIndex = testArray.Length - 1; for (int idx = 0; idx <= topIndex; idx++) { //------------------------------------------ //Создать экземпляр вспомогательного класса, //который расчленяет строку на три части // //Это неэкономный способ! //------------------------------------------- workerClass1 = new WastefulWorkerClass(testArray[idx]); //Если средним словом является "blue", заменить его на "orange" if (workerClass1.MiddleSegment == "blue") { //Заменить средний сегмент workerClass1.MiddleSegment = "orange"; //Заменить слово testArray[idx] = workerClass1.getWholeString(); } } //конец внутреннего цикла for }//конец внешнего цикла for //Получить время окончания теста PerformanceSampling.StopSample(0); System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(0)); }Листинг 8.4. Рабочий класс для первого тестового примера using System; public class WastefulWorkerClass { private string m_beginning_segment; public string BeginSegment { get { return m_beginning_segment; } set { m_beginning_segment = value; } } private string m_middle_segment; public string MiddleSegment { get { return m_middle_segment; } set { m_middle_segment = value; } } private string m_end_segment; public string EndSegment { get { return m_end_segment; } set { m_end_segment = value; } } public WastefulWorkexClass(string in_word) { int index_segment1; //Осуществляем поиск символов подчеркивания ("_") в строке index_segment1 = in_word.IndexOf("_",0); //B случае отсутствия символов "_" все, что нам нужно, это первый сегмент if (index_segment1 == -1) { m_beginning_segment = in_word; m_middle_segment = ""; m_end_segment = ""; return; } //Если присутствует символ "_", усечь его else { //Если первым символом является "_", то первым сегментом будет "" if (index_segment1 == 0) { m_beginning_segment = ""; } else { //Первый сегмент m_beginning_segment = in_word.Substring(0, index_segment1); } //Найти второй символ "_" int index_segment2; index_segment2 = in_word.IndexOf("_", index_segment1 + 1); //Второй символ "_" отсутствует if (index_segment2 == -1) { m_middle_segment = ""; m_end_segment = in_word.Substring(index_segment1 + 1); return; } //Установить последний сегмент m_middle_segment = in_word.Substring(index_segment1 + 1, index_segment2 - index_segment1 -1); m_end_segment = in word.Substring(index segment2 + 1); } //Возвращает все три сегмента, объединенные символами "_" public string getWholeString() { return m_beginning_segment + "_" + m_middle_segment + "_" + m_end_segment; } } //конец класса Повторно используйте размещенные в памяти объекты при любом удобном случаеСоздание экземпляра вспомогательного класса в каждой итерации цикла обработки является большим расточительством. Несмотря на относительно малые размеры объекта, содержащего всего лишь несколько элементов данных, его обработка приводит к дополнительным накладным расходам. Кроме того, каждый раз, когда создается очередной экземпляр объекта, прежний экземпляр освобождается. В результате этого образуется мусор, который впоследствии должен быть убран. От напрасного размещения объектов в памяти мы можем легко избавиться. Листинг 8.5. Тестовый пример, демонстрирующий уменьшение объема памяти, распределяемой для объектов (типичный образец улучшения первоначального варианта реализации интересующей нас функции)Примечание. В этом примере используется класс PerformanceSampling, определенный ранее в данной книге. private void button3_Click(object sender, System.EventArgs e) { //Вызвать сборщик мусора, чтобы тест //начинался с чистого состояния. //ПРИБЕГАЙТЕ К ЭТОЙ МЕРЕ ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ! Вызовы //сборщика мусора в программах вручную будут приводить к снижению //общей производительности приложений! System.GC.Collect(); string[] testArray = null; //-------------------------------------------- //Просмотреть элементы массива и найти //те из них, в которых средним словом является //"blue". Заменить "blue" на "orange" //-------------------------------------------- //Запустить секундомер! PerformanceSampling.StartSample(1, "LessWasteful"); //-------------------------------------------- //БОЛЕЕ ЭКОНОМНЫЙ СПОСОБ: Распределить память //для объекта до вхождения в цикл //-------------------------------------------- LessWastefulWorkerClass workerClass1; workerClass1 = new LessWastefulWorkerClass(); int outerLoop; for (outerLoop = 0; outerLoop < LOOP_SIZE; outerLoop++) { //Присвоить элементам массива значения, которые //мы хотим использовать при тестировании ResetTestArray(ref testArray); int topIndex = testArray.Length - 1; for(int idx = 0; idx <= topIndex; idx++) { //--------------------------------------------------------- //Теперь вместо повторного распределения памяти для объекта //нам достаточно лишь повторно воспользоваться им //--------------------------------------------------------- //workerClass1 = new WastefulWorkerClass( // testArray[topIndex]); workerClass1.ReuseClass(testArray[idx]); //Если средним словом является "blue", заменить его на "orange" if (workerClass1.MiddleSegment == "blue") { //Заменить средний сегмент workerClass1.MiddleSegment = "orange"; //Заменить слово testArray[idx] = workerClass1.getWholeString(); } } } //Остановить секундомер! PerformanceSampling.StopSample(1); System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(1)); }Листинг 8.6. Рабочий класс для второго тестового примера using System; public class LessWastefulWorkerClass { private string m_beginning_segment; public string BeginSegment { get { return m beginning_segment; } set { m_beginning_segment = value; } } private string m_middle_segment; public string MiddleSegment { get { return m_middle_segment; } set { m_middle segment = value; } } private string m_end_segment; public string EndSegment { get { return m_end_segment; } set { m_end_segment = value; } } public void ReuseClass(string in word) { //---------------------------------------------- //Для повторного использования класса необходимо //полностью очистить внутреннее состояние //---------------------------------------------- m_beginning_segment = ""; m_middle_segment = ""; m_end_segment = ""; int index_segment1; //Осуществляем поиск символов подчеркивания (" ") в строке index segment1 = in_word.IndexOf(" ",0); //B случае отсутствия символов " " все, что нам нужно, это первый сегмент if (index_segment1 == -1) { m_beginning_segment = in_word; return; } //Если присутствует символ " ", усечь его else { if (index_segment1 == 0) { } else { m_beginning_segment = in_word.Substring(0, index_segment1); } int index_segment2; index_segment2 = in_word.IndexOf("_", index_segment1 + 1); if (index_segment2 == -1) { m_end_segment = in_word.Substring(index_segment1 + 1); return; } //Установить последний сегмент m_middle_segment = in_word.Substring(index_segment1 + 1, index_segment2 - index_segment1 - 1); m_end_segment = in_word.Substring(index_segment2 + 1); } } public string getWholeString() { return m_beginning_segment + "_" + m_middle_segment + "_" + m_end_segment; } } Предшествующий код оставляет возможности для внесения дальнейших улучшений Избегайте размещения в памяти лишних объектовОбратите внимание на то, что в приведенном выше коде мы часто вычисляем множество величин, которые нам не нужны. В частности, мы генерируем в каждой итерации цикла, по крайней мере, три новых строки: одну для первого сегмента, одну для среднего сегмента и одну для конечного сегмента исходной строки. Например, строка big_blue_boat разбивается на три различных строки: big, blue и boat. Для создания этих строк требуется определенное время, а, кроме того, впоследствии мы должны освободить занимаемую ими память. В алгоритме выполняется проверка только среднего сегмента, в ходе которой устанавливается, совпадает ли он с некоторым конкретным значением (blue). Если совпадения нет. дальнейшая обработка не требуется. Это означает, что большую часть времени мы напрасно распределяем память для строк, предназначенных для размещения среднего и конечного сегментов, даже если они используются алгоритмом всего лишь для того, чтобы вновь собрать целую строку из отдельных кусочков. Что если вместо создания целых строк из кусочков старой строки в каждой итерации цикла мы будем просто сохранять символьные индексные значения, которые указывают нам, где находятся символы подчеркивания (_) в строке? Мы можем сохранять эти данные в виде целых чисел, накладные расходы для которых должны быть значительно меньше, чем при размещении новых строк. Если мы поступим именно таким образом, то сможем использовать исходные строковые и индексные значения для сравнения строк, начиная с первого символа подчеркивания и доходя до второго символа подчеркивания (например, blue_). Лишь в тех случаях, когда обнаруживается совпадение, нам потребуется создавать дополнительную строку для замены среднего сегмента. В большинстве случаев ситуация для нас намного улучшится и нам не надо будет распределять память для каких-либо объектов или строк. Лишь в тех случаях, когда обнаруживается совпадение средних сегментов, нам потребуется выполнять дополнительные строковые операции, но в любом случае нам придется выполнить не больше операций, чем выполнялось ранее. Как бы то ни было, хуже не будет. Листинг 8.7. Тестовый пример, демонстрирующий значительное уменьшение объема памяти, распределяемой для объектов (типичный образец существенной алгоритмической оптимизации первоначального варианта реализации интересующей нас функции)Примечание. В этом примере используется класс PerformanceSampling, определенный ранее в данной книге. private void button5_Click(object sender, System.EventArgs e) { //Вызвать сборщик мусора, чтобы тест //начинался с чистого состояния. //ПРИБЕГАЙТЕ К ЭТОЙ МЕРЕ ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ! Вызовы //сборщика мусора в программах вручную будут приводить к снижению //общей производительности приложений! System.GC.Collect(); string[] testArray = null; //-------------------------------------------- //Просмотреть элементы массива и найти //те из них, в которых средним словом является //"blue". Заменить "blue" на "orange" //-------------------------------------------- //Запустить секундомер перед началом выполнения теста PerformanceSampling.StartSample(2, "DefferedObjects"); //----------------------------------------------- //БОЛЕЕ ЭКОНОМНЫЙ СПОСОБ: Распределить память для //объекта до вхождения в цикл //----------------------------------------------- LessAllocationsWorkerClass workerClass1; workerClass1 = new LessAllocationsWorkerClass(); int outerLoop; for (outerLoop = 0; outerLoop < LOOP_SIZE; outerLoop++) { //Присвоить элементам массива значения, которые //мы хотим использовать при тестировании ResetTestArray(ref testArray); int topIndex = testArray.Length - 1; for(int idx = 0; idx <= topIndex; idx++) { //--------------------------------------------------------- //Более экономный способ: //Теперь вместо повторного распределения памяти для объекта //нам достаточно лишь повторно воспользоваться им //Кроме того: в этом варианте реализации дополнительные // строки НЕ создаются //--------------------------------------------------------- //workerClass1 = new WastefulWorkerClass( // testArray[topIndex]); workerClass1.ReuseClass(testArray[idx]); //Если средним словом является "blue", заменить его на "orange" //-------------------------------------------------- //Более экономный способ: //При таком способе сравнения не требуется создавать //никаких дополнительных строк //-------------------------------------------------- if (workerClass1.CompareMiddleSegment("blue") == 0) { //Заменить средний сегмент workerClass1.MiddleSegment = "orange"; //Заменить слово testArray[idx] = workerClass1.getWholeString(); } } } //Остановить секундомер! PerformanceSampling.StopSample(2); System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(2)); }Листинг 8.8. Рабочий класс для третьего тестового примера using System; public class LessAllocationsWorkerClass { public string MiddleSegment { set { m_middleSegmentNew= value; } } private string m_middleSegmentNew; private int m_index_1st_undscore; private int m_index_2nd undscore; private string m_stringIn; public void ReuseClass(string in_word) { //---------------------------------------------- //Для повторного использования класса необходимо //полностью очистить внутреннее состояние //---------------------------------------------- m_index_1st_undscore = -1; m_index_2nd_undscore = -1; m_middleSegmentNew= null; m_stringIn = in_word; //Это не приводит к созданию копии строки //Осуществляем поиск символов подчеркивания ("_") в строке m_index_1st_undscore = in_word.IndexOf("_",0); //B случае отсутствия символов "_" все, что нам нужно, это первый сегмент if (m_index_1st_undscore == -1) { return; } //Найти второй символ " " m_index 2nd_undscore = in_word.IndexOf(" ", m_index_1st_undscore + 1); } public int CompareMiddleSegment(string compareTo) { //B случае отсутствия второго символа "_" отсутствует и средний сегмент if (m_index_2nd_undscore < 0) { //Если мы сравниваем с пустой строкой, //то это означает совпадение if((compareTo == null) || (compareTo == "")) {return 0;} return -1; } //Сравнить средний сегмент с первым и вторым сегментами return System.String.Compare( m_stringIn, m_index_1st_undscore + 1, compareTo, 0, m_index_2nd_undscore - m_index_1st_undscore -1); } public string getWholeString() { //Если полученный средний сегмент не является новым, //возвратить исходный сегмент if (m_middleSegmentNew == null) { return m_stringIn; } //Создать возвращаемую строку return m_stringIn.Substring(0, m_index_1st_undscore + 1) + m_middleSegmentNew + m_stringIn.Substring(m_index_2nd_undscore, m_stringIn.Length - m_index_2nd_undscore); } } Анализ описанных выше шагов последовательной оптимизацииОбычно в тонкой настройке алгоритмов таятся значительные резервы. Самое важное при этом — это контролировать, обеспечивает ли выполнение настройки выигрыш в производительности, на который вы рассчитывали. Некоторыми своими "усовершенствованиями" вы можете непреднамеренно ухудшить производительность из-за того, что с ними связано распределение памяти, о котором вы можете не знать, или в силу каких-либо других причин. В процессе разработки приведенного выше кода у меня несколько раз возникали ситуации, когда я считал, что вносимые изменения должны улучшить результаты, но после проведения соответствующих измерений и при более глубоком рассмотрении оказывалось, что эти изменения приносили только вред. Всегда измеряйте показатели производительности и проводите их сравнительный анализ для различных вариантов реализации! Кроме того, очень важно проводить тестирование на фактическом оборудовании, для которого предназначено ваше приложение, чтобы лучше почувствовать реальные условия работы с ним "на устройстве". Эмуляторы очень удобно использовать в процессе проектирования и базовой настройки приложения, но результаты, полученные на физическом устройстве, могут быть другими из-за различий в свойствах процессоров, памяти и других факторов. Одни программы могут выполняться на физических устройствах быстрее, другие — медленнее. Последнее слово всегда остается за фактическим оборудованием, которое будут использовать конечные пользователи. По тем же причинам очень важно измерять производительность при выполнении программы с подключенным отладчиком и без него. В некоторых случаях подключение отладчика резко снижает производительность. Результаты тестирования трех различных алгоритмов, обсуждаемых нами, представлены в таблицах 8.1 и 8.2. Таблица 8.1. Результаты тестирования алгоритмов (в секундах) на эмуляторе Pocket PC с вычислением 8000 циклов
Таблица 8.2. Результаты тестирования алгоритмов (в секундах) на физическом устройстве Pocket PC с вычислением 2000 циклов
Анализ приведенных выше результатов говорит о следующем: ■ Применение первого варианта оптимизации, основанного на повторном использовании объектов вместо распределения памяти, обеспечило лишь самое минимальное повышение производительности. Вероятно, такое поведение приложения объясняется небольшими размерами самих объектов и используемых данных. Уже зная полученные результаты, можно отметить, что в них нет ничего удивительного. Учитывая легкость проведения этого вида оптимизации, который требует включения всего лишь нескольких новых строк кода, он заслуживает интереса. Дополнительным преимуществом этого способа, которое не отражают приведенные выше цифры, является то, что исключение размещения в памяти новых объектов из цикла с большим количеством повторений должно приводить к значительному уменьшению "объектного мусора" в нашем приложении. В результате этого сборка мусора будет осуществляться реже, следствием чего должно быть значительное улучшение общей производительности. Этот вид оптимизации не привел к существенному повышению скорости выполнения приложения, но и не ухудшил ее, а, кроме того, обеспечил значительное уменьшение объема образующегося "мусора". ■ Второй из проверенных нами вариантов оптимизации, заключающийся в отказе от распределения памяти для нескольких строковых объектов и использовании вместо этого строковых индексов, оказал на производительность приложения значительное воздействие. Благодаря внесению изменений в проект вспомогательного класса и задержке создания строкового класса до тех пор, пока это действительно не потребуется, мы непосредственно увеличили общую производительность алгоритма более чем на треть. Кроме того, как и в рассмотренном выше случае, нам удалось значительно уменьшить количество "мусора", образующегося в результате работы нашего алгоритма. Следствием этого явилось уменьшение общего объема "мусора", а также более ровное и быстрое выполнение приложения. ■ Закономерности изменения производительности в ряду вариантов оптимизации для эмулятора и физических устройств Pocket PC в основном совпадают, но между абсолютными показателями производительности алгоритма для этих двух случае наблюдаются разительные отличия. В нашем примере (распределение памяти для строк) результатом оптимизации явилось одинаковое улучшение производительности как на эмуляторе, так и на физических устройствах, но самый оптимальный вариант алгоритма выполнялся на эмуляторе со скоростью 934 итерации в секунду, а на физическом устройстве — 122 итерации в секунду. Таким образом, данный алгоритм выполняется на эмуляторе в 7,6 раз быстрее по сравнению с физическим устройством. Если этот алгоритм является критическим, и мы собираемся применять его ко многим тысячам единиц данных, то мы должны позаботиться об организации обратной связи с пользователями приложения на время проведения вычислений. В этой связи может потребоваться привлечение фоновых потоков выполнения для обработки данных или использование меньших объемов данных в каждый момент времени. Единственный способ получения реальных результатов оценки производительности — это выполнение приложения на реальных устройствах с использованием реальных объемов данных. Уделяйте особое внимание тому, как используются строки в ваших алгоритмахЧрезвычайная широта применения и необычайная полезность строк при создании программного обеспечения делают этот специальный тип данных уникальным. Часто строки представляют обычный текст, но нередко они используются и для передачи машинных данных, например строк запросов баз данных. Короче говоря, строки вездесущи, а байтовый тип данных применяется в большинстве приложений там, где надо, и там, где не надо. Современные языки программирования позволяют очень легко работать со строками, создавать их, разбивать, копировать и объединять. Рассмотрим, например, следующие простые операторы. string str1 = "foo"; //Размещает в памяти строковый объект string str2 = "bar"; //Размещает в памяти строковый объект string str3 = str1 + str2; //Размещает в памяти строковый объект string str3 = str3 + str3; //Размещает в памяти строковый объект Каждый из этих операторов создает типы и размещает данные в памяти, и при этом нам даже не приходится вызывать никаких функций! Многие разработчики пользуются строками настолько бездумно, что легко могут допустить их некорректное использование. Не оптимизированная обработка строк является одной из наиболее вероятных причин плохой производительности. Ниже представлены некоторые рекомендации и правила, которыми следует руководствоваться при работе со строками. (При этом подразумевается, что вы работаете в .NET Framework/.NET Compact Framework, однако аналогичные правила будут действовать и в других средах. Более детальные разъяснения вы найдете в соответствующем справочном руководстве для своей среды.) ■ Строки неизменчивы (постоянны). Этот странный термин неизменчивый (immutable) просто означает, что текстовые данные строки не могут быть изменены в памяти. Те операции в коде, которые, как вам кажется, изменяют данные строки, на самом деле создают новую строку. Постоянство обладает некоторыми весьма привлекательными свойствами. Например, поскольку строковые данные сами по себе являются статическими, несколько переменных могут указывать на одни и те же данные; благодаря этому присвоение одной строковой переменной значения другой сводится к простому копированию "указателя" вместо глубокого копирования всех данных, которые ему соответствуют. Отрицательной стороной неизменчивости является невозможность изменения данных. Если вы хотите изменить, добавить или отсечь данные, то эти изменения будут отражаться в новой копии строки. ■ Когда на строковые данные не ссылается ни одна "активная" ("live") переменная, они становятся "мусором". Рассмотрим пример: string str1 = "foo"; //"foo" — статические данные, скомпилированные //в двоичные данные вашего приложения string str2 = str1 + str1; //только что была создана новая строка, явля- //ющаяся результатом конкатенации двух строк str2 = "bar"; //Поскольку отсутствуют другие переменные, указываю- //щие на те данные, на которые указывала переменная str2, //эти данные становятся мусором, и память должна быть //очищена от них. ■ Если вы хотите сослаться на некоторую часть строки, то во многих случаях это проще всего сделать, используя целочисленные индексы в строке. Поскольку строки — это данные, представленные массивами символов, то использование индексов для получения этих данных не составляет труда. Существует множество функций, позволяющих осуществлять поиск и просмотр данных внутри строк (но только не изменять эти данные!). ■ Если вы создаете новые строки внутри циклов, настоятельно рекомендуется рассмотреть возможность использования объекта StringBuilder. Все виды строк создаются на основе других переменных, обрабатываемых в циклах. Типичным примером динамического создания строк может служить цикл, генерирующий текстовый отчет, каждая строка которого содержит следующие данные: //Неэффективный код, выполняющийся внутри цикла... { myString = myString +"CustomerID: " + System.Convert.ToString(customer[idx].id) + ", Name: " + System.Convert.ToString(customer[idx].name); } Вместо того чтобы конкатенировать строки и создавать новую строку, для создания отчета можно было бы использовать класс StringBuilder. Класс StringBuilder очень удобно использовать для работы с массивами переменной размерности с целью создания строк. Он позволяет эффективно изменять длину или содержимое массива и, что самое важное, создавать новые строки на основе символьных массивов. Обязательно изучите класс StringBuilder, поскольку умение использовать его имеет решающее значение для написания эффективных алгоритмов, генерирующих строковые данные. ■ Измеряйте объективные количественные показатели своих алгоритмов. Занимаясь написанием алгоритма обработки строк, тестируйте его быстродействие! Испробуйте несколько различных подходов. Вы очень быстро научитесь распознавать, какой алгоритм будет эффективным, а какой — нет. Пример эффективного создания строкВ листинге 8.9 представлены два аналогичных алгоритма, которые приводят к одному и тому же результату. В обоих алгоритмах осуществляется инкрементирование счетчика, и каждый раз, когда значение счетчика увеличивается, его строковое представление добавляется в расширяемый фрагмент текста. Оба алгоритма выполняют одинаковое количество итераций и характеризуются одинаковой степенью сложности написания. И, тем не менее, один из них работает гораздо быстрее другого. Листинг 8.9. Сравнение эффективности использования строк и класса StringBuilder в алгоритмахПримечание. В этом примере используется класс PerformanceSampling, определенный ранее в данной книге. const int COUNT_UNTIL = 300; const int LOOP_ITERATIONS = 40; //--------------------------------------------------------- //HE ОЧЕНЬ ЭФФЕКТИВНЫЙ АЛГОРИТМ! // //Для имитации создания типичного набора строк используются //обычные строки //--------------------------------------------------------- private void button1_Click(object sender, System.EventArgs e) { //Вызвать сборщик мусора, чтобы тест //начинался с чистого состояния. //ПРИБЕГАЙТЕ К ЭТОЙ МЕРЕ ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ! Вызовы //сборщика мусора в программах вручную будут приводить //к снижению общей производительности приложений! System.GC.Collect(); int numberToStore = 0; PerformanceSampling.StartSample(0, "StringAllocaitons"); string total_result = ""; for (int outer_loop = 0; outer loop < LOOP_ITERATIONS; outer_loop++) { //Сбросить старый результат total_result = ""; //Выполнять цикл до максимального значения x_counter, каждый //раз присоединяя очередную тестовую строку к рабочей строке for (int x_counter = 0; x_counter < COUNT_UNTIL; x_counter++) { total_result = total_result + numberToStore.ToString() + ", "; //Увеличить значение счетчика numberToStore ++; } } PerformanceSampling.StopSample(0); //Отобразить длину строки System.Windows.Forms.MessageBox.Show("Длина строки: " + total_result.Length.ToString()); //Отобразить строку System.Windows.Forms.MessageBox.Show("Строка : " + total_result); //Отобразить длительность интервала времени, ушедшего на вычисления System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(0)); } //--------------------------------------------------------- //ГОРАЗДО БОЛЕЕ ЭФФЕКТИВНЫЙ АЛГОРИТМ! // //Для имитации создания типичного набора строк используется //объект StringBuilder //--------------------------------------------------------- private void button2_Click(object sender, System.EventArgs e) { //Вызвать сборщик мусора, чтобы тест //начинался с чистого состояния. //ПРИБЕГАЙТЕ К ЭТОЙ МЕРЕ ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ! Вызовы //сборщика мусора в программах вручную будут приводить //к снижению общей производительности приложений! System.GC.Collect(); System.Text.StringBuilder sb = new System.Text.StringBuilder(); string total_result = ""; int numberToStore = 0; PerformanceSampling.StartSample(1, "StringBuilder"); for (int outer_loop = 0; outer_loop < LOOP_ITERATIONS; outer_loop++) { //Очистить объект StringBuilder (не создавая нового объекта) sb.Length = 0; //Очистить строку со старым результатом total_result = ""; //Выполнять цикл до максимального значения x_counter, каждый раз //присоединяя очередную тестовую строку к рабочей строке for (int x_counter = 0; x_counter < COUNT_UNTIL; x_counter++) { sb.Append(numberToStore); sb.Append(", "); //Увеличить значение счетчика numberToStore++; } //Имитируем выполнение некоторых операций над строкой... total_result = sb.ToString(); } PerformanceSampling.StopSample(1); //Отобразить длину строки System.Windows.Forms.MessageBox.Show("Длина строки: " + total_result.Length.ToString()); //Отобразить строку System.Windows.Forms.MessageBox.Show("String : " + total_result); //Отобразить длительность интервала времени, ушедшего на вычисления System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(1)); } Таблица 8.3. Сравнение результатов (в секундах) для 40×300 циклов, выполненных с использованием эмулятора
Таблица 8.4. Сравнение результатов (в секундах) для 40×300 циклов, выполненных на физическом устройстве Pocket PC
Ниже представлен анализ полученных результатов. ■ Конструируя строки из нескольких сегментов с помощью класса StringBuilder, вы можете добиться гораздо более высокой эффективности, чем при работе с отдельными постоянными строками. Конкатенация строк и другие операции со строками, выполняемые внутри циклов, могут приводить к большим накладным расходов, обусловленным многократным размещением и освобождением объектов, находящихся в памяти. В отличие от этого класс StringBuilder обрабатывает данные не как постоянные строки, а как массив символов переменной размерности, и обеспечивает эффективное управление его длиной, изменяя ее в соответствии с необходимостью. Если приложению требуется разместить в памяти постоянный строковый объект, то это можно сделать, вызвав метод ToString(). Класс StringBuilder может с большим успехом использоваться при обработке текста ■ Создание новых строк в циклах приводит к образованию большого количества "мусора". Если имеется достаточный объем свободной памяти, сборщик мусора при необходимости может выполняться в процессе работы алгоритма. Он может выполняться несколько раз, а в условиях острого дефицита свободной памяти он может работать почти непрерывно. Усиливающаяся нехватка памяти приводит к постепенному ухудшению производительности. Даже после того как выполнение алгоритма завершается, остается много мусора, от которого следует очистить память. При этом вы должны найти все ранее распределенные, а затем удаленные объекты и окончательно освободить от них память. ■ В некоторых случаях результаты оптимизации для физического мобильного устройства могут превосходить результаты для эмулятора, выполняющегося на гораздо более мощной машине. В рассмотренном выше примере, в котором память распределялась для строк, прирост производительности в результате полной оптимизации для физического устройства Pocket PC был больше, чем в случае выполнения эмулятора на моем лэптопе. Однако при использовании объектов StringBuilder наблюдается обратная ситуация. В отношении абсолютной производительности метод использование объектов StringBuilder демонстрирует явное превосходство над методом, использующим распределение памяти для строк. В качестве грубого ориентира при сопоставлении алгоритмов можно руководствоваться тем, что тот алгоритм, который на эмуляторе, установленном на персональном компьютере, выполняется быстрее, окажется более быстрым и на мобильном устройстве; в то же время, если требуется более точная оценка, целесообразно всегда проводить тестирование производительности на физическом мобильном оборудовании. РезюмеРазрабатывая схему управления памятью в приложении, важно анализировать, что происходит как на "макроскопическом" уровне приложения, так и на "микроскопическом" уровне алгоритма. Нa макроскопическом уровне важно иметь модель памяти, которая обеспечивает экономное потребление памяти устройства, но при этом позволяет вам держать под рукой данные и ресурсы, которые в вашем приложении используются наиболее часто. При решении этой задачи для ресурсов приложения вам может очень пригодиться подход, основанный на использовании конечного автомата. Что касается пользовательских данных приложения, то в этом случае целесообразно создать класс, предназначенный для управления объемом данных приложения, которые должны храниться в памяти в каждый момент времени. Этот класс будет играть роль инкапсулированного конечного автомата, которому известно, каким образом воспользоваться новыми данными, когда в этом возникает необходимость, или избавиться от устаревших данных, которые только напрасно занимают память. Обязательно вызывайте метод Dispose(), когда заканчиваете работу с объектами, для которых он предусмотрен; эта мера обеспечит принудительное освобождение неуправляемых ресурсов, удерживаемых объектом, и увеличит общую пропускную способность системы. На уровне алгоритма важно не только выбрать наиболее подходящий алгоритм обработки данных, но и эффективно реализовать его. При реализации алгоритма вы должны стремиться к тому, чтобы объем памяти, распределяемой для объектов, был как можно меньшим; для кода, выполняющегося в цикле, это приобретает еще большее значение. Особого внимания заслуживают строки, чрезвычайная широта применения которых повышает вероятность того, что часть памяти, связанная с распределением и освобождением строк, будет расходоваться понапрасну. В случае строковых алгоритмов наибольший интерес представляют два подхода: 1) использование индексов для ссылки на содержащиеся в строке данные, а не извлечение подстрок в виде отдельных строк, и 2) создание строк с помощью класса StringBuilder (или его эквивалентов в случае других сред выполнения). В процессе написания своих алгоритмов проявляйте особую осмотрительность при создании и освобождении объектов, поскольку распределение памяти для объектов и их инициализация требуют определенного времени, а объекты в конечном счете превращаются в "мусор", от которого среда выполнения должна избавляться. Создание мусора означает необходимость выполнения лишней работы по очистке системы от него, что снижает общую производительность приложения. Концепция объектов необычайно плодотворна, однако их неправильное использование влечет за собой дополнительные накладные расходы; в процессе проектирования алгоритмов эти соображения необходимо всегда учитывать. Среда выполнения вашего мобильного приложения во многом может быть уподоблена небольшой квартире- Пока такая квартира не слишком забита вещами, проживание в ней может доставлять одно удовольствие. Стоит, однако, вещам загромоздить ее, как вам станет трудно перемещаться по ней и вообще что-либо делать. Если в процессе вашей ежедневной деятельности создается много мусора, то вам приходится часто выносить мусорное ведро и тратить время на наведение порядка вместо того, чтобы заниматься полезной работой. На макроуровне в обыденной жизни следует стремиться к тому, чтобы жилье было опрятным и просторным, а все необходимые вещи были всегда под рукой. Что касается микроуровня, то следует просто не мусорить! |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||