|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
ГЛАВА 14Шаг 3: разработка подходящей модели данных
Введение в модели доступа к данным, используемые в мобильных приложенияхПосле того как вы приняли решение относительно сферы применения вашего приложения, настроились на использование методологии разработки, ориентированной на обеспечение высокой производительности, и определились с моделью пользовательского интерфейса, важно подобрать для мобильного приложения подходящую модель доступа к данным. Модель доступа к данным описывает, каким образом приложение удовлетворяет свои потребности в извлечении и хранении долгосрочной информации. Как уже обсуждалось в данной книге, модели памяти определяют, каким образом приложение управляет данными и ресурсами, находящимися в памяти; точно так же, вашему мобильному приложению потребуется модель доступа к данным, которая определяет, каким образом осуществляется обмен данными между приложением и долговременными хранилищами. Практически любое более или менее значимое приложение работает с данными, существующими в течение длительного времени. Эти данные могут либо находиться в структурированной базе данных на сервере или устройстве, либо храниться в индивидуально управляемых файлах с использованием менее формализованных способов. В приложениях научно-производственного характера, а также приложениях, предназначенных для повышения производительности труда, операции, связанные с вводом, манипулированием, анализом и отображением данных, занимают центральное место. Мощные игры также работают с данными и часто хранят их в течение промежутков времени, разделяющих игровые сеансы. В целом, можно полагать, что чем сложнее и полезнее приложение, тем больше ему приходится работать с долговременными данными. Что касается доступа к данным, то между мобильными приложениями и их настольными и серверными аналогами имеется важное отличие, суть которого заключается в том, что связь между мобильным устройством и серверами баз данных, находящимися вне устройства, обычно устанавливается лишь на короткие промежутки времени. Если настольному приложению не удается получить доступ к серверу, то обычно это означает нарушение нормального режима работы, которое требуется устранить. В то же время, отсутствие доступа к серверу в случае мобильных приложений — это их обычное состояние; исключительными ситуациями для них являются, скорее, сеансы связи с сервером, поскольку либо необходимость в них возникает реже, либо их стоимость высока. Из-за этого фактора управление данными, создание их динамических представлений и внесение изменений пользователем могут представлять некоторые трудности. Данные характеризуются как длительностью их существования в памяти, так и длительностью их долговременного хранения; при проектировании мобильного приложения следует учитывать обе эти характеристики. Модель данных вашего мобильного приложения представляет состояние, которым требуется управлять, чтобы создать для пользователя комфортные условия работы с приложением. Распространенной ошибкой разработчиков является простой перенос на мобильные устройства моделей доступа к данным, которые применяются на настольных компьютерах и серверах, в неизменном виде, без тщательного анализа того, как это повлияет на использование памяти. Тот факт, что с подобной ошибкой приходится сталкиваться часто, вполне объясним, поскольку с точки зрения синтаксиса все программные модели аналогичны друг другу, и во многих случаях код, выполняющийся на настольных компьютерах и серверах, легко переносится на устройства. В то же время, простой перенос стратегий доступа к данным с настольных компьютеров и серверов на мобильные устройства позволяет получить удовлетворительные результаты лишь в редких случаях. Причину этого можно описать двумя словами — "состояние памяти". Более высокая степень абстрагирования часто достигается за счет создания объектов на дополнительных уровнях абстракции. Как создание, так и уничтожение этих объектов приводят к более жестким условиям использования памяти и занимают процессорное время. Для мобильных приложений вопрос о выборе модели доступа к данным оказывается непосредственно связанным с вопросом о выборе модели управления памятью в гораздо большей степени, чем в случае приложений для настольных компьютеров. Если памяти, необходимой для обслуживания потребностей обеих моделей, едва хватает, то это может серьезно сказаться на производительности приложения. Аналогично средствам для работы с XML-данными, существуют низкоуровневые API-интерфейсы, не использующие состояния, и высокоуровневые программные модели доступа к памяти, предлагающие более развитые возможности, но кумулятивно изменяющие состояние в процессе выполнения. Использование высокоуровневых моделей доступа к данным позволяет сократить сроки написания кода, однако за это приходится платить увеличением объема памяти, используемой для хранения информации о состоянии. Если эта информация действительно нужна и используется мобильным приложением, а объем данных, которыми при этом приходится оперировать в памяти, можно поддерживать на низком уровне, то привлечение стратегий доступа к данным, основанных на использовании состояний, является оправданным. И наоборот, если объем данных, которые приходится хранить в памяти, велик или необходимость в дополнительных возможностях, предоставляемых высокоуровневой моделью программирования, отсутствует, то разработчик, выбравший этот путь, будет только напрасно тратить драгоценную память мобильного устройства. Часто хранение тех же данных можно организовать гораздо более эффективным образом за счет отказа от универсальной программной модели доступа к данным и использования наборов типов, специально предназначенных для работы с конкретными данными, которыми необходимо управлять. Неэкономное использование памяти окажет значительное отрицательное влияние на производительность мобильного приложения; при этом проблемы производительности проявятся либо немедленно, либо впоследствии, когда вы попытаетесь ввести в приложение дополнительную функциональность, поскольку для организации поддержки новых средств вам просто не хватит резерва производительности. По возможности, старайтесь избегать излишнего усложнения приложения. Впервые приступая к реализации стратегий доступа к данным на мобильных устройствах, разработчики, профессиональная деятельность которых была до этого связана с настольными компьютерами и серверами, обычно делают вывод, что мобильные устройства просто не в состоянии обеспечить тот уровень производительности, который требуется. На самом деле это почти всегда не соответствует действительности. Что необходимо сделать — так это тщательно проанализировать требования к доступу данных, предъявляемые мобильным приложением, и спроектировать такую модель данных, которая наилучшим образом соответствовала бы этим требованиям. Например, если данные в основном только считываются, то можно добиться выигрыша в эффективности, сохраняя данные в памяти с использованием нестандартного формата, оптимизированного для уменьшения суммарного объема данных и увеличения скорости проведения поиска, а не для обновления данных; в случае настольных компьютеров эта мера может привести лишь к незначительному увеличению производительности приложения, тогда как в случае мобильных устройств достигаемое при этом улучшение результатов может быть разительным. Выбор подходящих абстракций для хранения данных в памятиЧтобы данные, возвращенные в результате запроса к базе данных или считанные из файла, можно было просматривать и манипулировать ими, они должны храниться в памяти. Существует два основных способа работы с такими данными, находящимися в памяти: 1. Применение универсальной абстрактной модели. Для работы с данными, извлекаемыми из баз данных, во многих программных каркасах предлагаются абстрактные модели. В .NET Compact Framework такой моделью является ADO.NET, использование которой описывается далее в этой главе; другие каркасы поддерживают другие модели. Достоинством абстрактных моделей является их гибкость. Данные, извлеченные из баз данных, хранятся в обобщенных таблицах и строках объектов. В каждой строке содержатся поля, соответствующие определенным столбцам. Таблицу образует сетка, состоящая из строк и столбцов. Таблицы можно группировать в наборы, причем для описания отношений между столбцами различных таблиц применяются дополнительные таблицы. Если выполняется обобщенный запрос к базе данных и заранее не известно, какого рода данные будут получены в ответ на этот запрос, то сохранение их в подобного рода обобщенном формате является необходимостью. Современные развитые модели доступа к данным могут также отслеживать внесение локальных изменений. Впоследствии эти изменения могут быть отвергнуты, приняты или иным образом приведены в соответствие с данными, хранящимися в базе данных. Кроме того, различные программные каркасы для доступа к данным поддерживают выполнение транзакций и локальное создание гибких представлений данных. Существуют также обобщенные модели связывания данных, которые обеспечивают связывание табличных данных с элементами пользовательского интерфейса. Эти универсальные модели программирования доступа к данным обладают высокой гибкостью, устойчивы к изменению формата базы данных и обеспечивают абстракции, предназначенные для просмотра типов данных, с которыми приходится работать, во время выполнения. Подобная гибкость дается за счет введения дополнительных объектов. Эти объекты содержат метаданные (метаданные — суть информация об информации), хранят отношения между различными элементами данных и отслеживают вносимые изменения. При использовании таких высокоуровневых технологий доступа к данным, хранимым в памяти, ваше приложение фактически создает в памяти базу данных; обладая значительными возможностями, этот подход предъявляет высокие требования к вычислительным ресурсам и памяти 2. Применение пользовательской модели, приспособленной для работы с вашими данными. Противоположностью абстрактной модели для работы с данными является "подход для бедных", основанный на создании пользовательской реализации, которая содержит лишь то, что требуется для хранения и использования данных. При применении пользовательской стратегии доступа к данным ваше мобильное приложение самостоятельно распоряжается абстракциями, предлагаемыми встроенной в память базой данных обобщенных строк, столбцов, таблиц и отношений, и выбирает способ хранения данных в формате, который больше всего подходит для решаемой задачи. Обычно для этой цели применяется массив простых типов, которые содержат данные. Эта пользовательская модель во многом лишена гибкости универсального подхода и вынуждена брать на себя заботу об обновлении данных и управлении отношениями между ними. Его преимущество состоит в том, что за счет использования исключительно тех объектов, без которых нельзя обойтись, у приложения появляется возможность значительно снизить объем памяти, занимаемой информацией о состоянии. Если данные, с которыми ведется работа, можно легко представить в виде единственной таблицы, а отношения между ними не отличаются сложностью, то приспособленный для конкретных целей пользовательский формат является отличным решением. Выбор наиболее подходящей модели определяется объемом и сложностью используемых данных. Было бы непозволительной ошибкой строить собственную модель данных, если они связаны между собой сложной системой отношений, которая нуждается в управлении и в представлениях в памяти мобильного приложения. Вместе с тем, если ваши данные состоят из нескольких простых полей в единственной таблице базы данных, а данные предназначены только для чтения, то было бы глупо останавливать свой выбор на сложной модели данных с поддержкой состояния, если простой массив данных позволяет отлично справиться с задачей. Вполне вероятно, что потребности в данных вашего приложения занимают промежуточное положение между этими двумя крайними случаями, и вам придется испытать несколько различных моделей, чтобы, в конечном счете, выбрать ту из них, которая в наибольшей степени соответствует вашим запросам. Как ранее обсуждалось, этот выбор аналогичен принятию разработчиками мобильных приложений решения о том, какую технологию следует применить при работе с XML-данными. Разработчик должен выбирать между потенциальной простотой проектирования и реализации и эффективностью выполнения приложения. Выбор подходящей модели данных, требующих долговременного храненияМодель долговременного хранения данных описывает, куда направляется информация после того, как приложение завершает работу. Даже мобильные устройства, которые включены постоянно и выполняют приложения на фоне, нуждаются в безопасном и структурированном хранилище долговременных данных. Типичным примером такого приложения в случае мобильных телефонов является электронная записная книжка (Personal Information Manager — PIM). Пользователь, разместивший в телефоне свою адресную книгу, рассчитывает на возможность доступа к этим данным вне зависимости от того, в каком состоянии находится телефон. Если это только вообще возможно, для таких данных должна автоматически создаваться резервная копия на сервере или настольном компьютере, чтобы их можно было быстро восстановить в случае сбоя долговременного запоминающего устройства телефона. Выбирая модель долговременного хранения данных мобильного приложения, вы должны ответить на два основных вопроса: 1. Должны ли данные храниться в файле или в базе данных? Если объем подлежащих хранению данных небольшой, то для этого, вероятно, лучше всего воспользоваться текстовым файлом. Если необходимо обеспечить максимально благоприятные условия для переноса файла с одного устройства на другое, то отличным выбором будет XML. В то же время, если ваше приложение работает с большими объемами данных, к которым требуется произвольный доступ, если необходимо обеспечить безопасность данных или если вы хотите использовать расширенные запросы, транзакции и синхронизацию данных, то наилучшим решением будет база данных. Основной недостаток использования баз данных состоит в том, что это влечет за собой дополнительные накладные расходы, а также необходимость дополнительной настройки, которая может потребоваться для развертывания приложения. 2. Точно так же как и в случае настольных приложений, можно либо обращаться непосредственно к базам данных, выполняющимся на сервере, либо хранить базы данных локально. Преимуществом баз данных, размещаемых на устройстве, является их доступность; вы можете обратиться к такой базе данных в любой момент, независимо от наличия соединения с сервером. Если необходимо получать доступ к большим объемам данных, то использование локальной базы данных может оказаться гораздо более эффективным, нежели пересылка результатов запросов на устройство через сравнительно медленное беспроводное соединение. К недостаткам локальных баз данных относятся дополнительная сложность развертывания приложения и необходимость в дополнительном объеме памяти для базы данных. Важно также знать, что различные мобильные устройства обладают различными возможностями поддержки локальных баз данных. Так, на момент написания данной книги база данных SQL СЕ поддерживалась на Pocket PC, но не поддерживалась на смартфонах. Если ваше приложение не может рассчитывать на использование базы данных на локальном устройстве, то вам, вероятнее всего, придется предусмотреть пользовательский механизм локального кэширования данных, которые являются для вас наиболее важными, к которым чаще всего производится обращение или доступ к которым стоит слишком дорого. Какой способ хранения данных лучше использовать: флэш-память или файл в ОЗУ? Специфика .NET Compact Framework: ADO.NETADO.NET — мощная многоуровневая программная модель, предназначенная для работы с реляционными данными любого вида. ADO.NET доступна на настольных компьютерах и серверах как часть .NET Framework, а на устройствах — как часть .NET Compact Framework. Поддержка ADO.NET в .NET Compact Framework основана на подмножестве программной модели, предназначенной для настольных компьютеров и серверов. Ключевым новшеством в модели данных ADO.NET для серверов, настольных компьютеров и устройств является полное отделение объекта ADO.NET DataSet от источника данных. Как только данные попали в ADO.NET DataSet, их можно сериализовать в виде XML-данных и сохранить в локальном файле или передать по сети на сервер, настольный компьютер или мобильное устройство. Между объектом ADO.NET DataSet и базами данных, предоставившими данные, не требуется поддерживать постоянное соединение; это обстоятельство является замечательным с точки зрения масштабируемости серверов, поскольку необходимость в поддержании постоянного соединения отрицательно воздействует на этот их аспект. Для работы с базами данных использование в приложении объекта ADO.NET не является обязательным Элементарные сведения об объектах ADO.NET DataSetADO.NET предлагает множество мощных концепций, которые поначалу кажутся сложными и обескураживают пользователей, привыкших работать с другими моделями доступа к данным. На самом же деле использовать ADO.NET довольно просто, но это требует от разработчика вдумчивого отношения к этой модели и означает отказ от понятия курсора данных как центрального механизма для работы с данными. Чтобы вы смогли лучше во всем разобраться, целесообразно сравнить ADO.NET с ее предшественницей — технологией ADO. Как говорит само название, объект ADO.NET DataSet теснее связан с математической идеей "набора данных" (data set), чем с традиционной идеей ADO о "наборе записей" (record set), который представляет строки записей в таблице и предоставляет курсор, позволяющий переходить от одной записи к другой. Объекты ADO.NET DataSet "не имеют курсора" в том смысле, что в этом случае понятие текущей записи и курсора, осуществляющего переключение контекста при переходе от записи к записи, отсутствует. В ADO.NET DataSet все записи просто существуют в виде набора и допускают произвольные переходы между записями без использования курсора, отслеживающего текущую запись. Кроме того, объекты DataSet не являются специфичными по отношению к таблицам; объект ADO.NET DataSet может содержать любое количество таблиц данных, равно как и любое количество информации об отношениях между таблицами. Прежние объекты ADO RecordSet позволяют проходить по одной таблице, содержащую информацию, тогда как объекты ADO.NET DataSet позволяют исследовать одну или несколько таблиц данных. Создание мостика между подходом, основанным на наборах данных, и моделью, в которой для работы с данными используются строки, обеспечивается объектами ADO.NET DataView и DataTable. Один объект DataSet может содержать любое количество объектов DataTable. Таблица данных (data table) фактически является массивом объектов, аналогичным таблице в базе данных. Объекты DataView — это объекты, предоставляющие методы фильтрации и сортировки поверх объектов DataTable, что позволяет добираться среди содержимого объекта DataSet до данных, которые представляют непосредственный интерес для вашего приложения. Объекты DataView могут также предоставлять отсортированное представление данных (data view), в котором данные упорядочиваются наиболее удобным для использования в приложении и отображения способом. С одной таблицей DataTable может быть связано произвольное количество объектов DataView, для каждого из которых определены свои критерии сортировки и фильтрации, позволяющие создавать пользовательские представления данных. На настольных компьютерах и серверах .NET Framework поддерживает как "типизированные", так и "нетипизированные" объекты DataSet. В .NET Compact Framework специально поддерживаются только "нетипизированные" объекты DataSet. Может показаться, что тем самым создаются определенные ограничения, однако в действительности это не так, поскольку типизированные объекты DataSet являются просто классами, построенными поверх нетипизированных объектов DataSet, которые жестко связывают имена типизированных полей с лежащими в их основе элементами нетипизированных объектов DataSet. Поскольку типизированный объект DataSet строится поверх нетипизированного класса DataSet, то он, по сути, представляет собой удобную в использовании, но несколько медленнее работающую абстракцию. Приложения, в которых нетипизированные объекты DataSet используются корректным образом, путем поиска и кэширования объектов DataColumn используемых ими столбцов (columns) (в отличие от поиска полей по именам при каждом их использовании), демонстрируют такую же или даже еще лучшую производительность по сравнению с теми, в которых используются типизированные объекты DataSet. Очень короткий пример использования объектов DataSet, DataTables и XMLЧтобы продемонстрировать основы работы с объектами ADO.NET DataSet, полезно обратиться к примеру. В документации .NET Framework содержится исчерпывающее описание ADO.NET и объектов DataSet. В примере будут показаны лишь самые элементарные операции создания и использования объектов DataSet с целью установления контекста для обсуждения использования ADO.NET на мобильных устройствах. Приведенный в листинге 14.1 код позволяет создать приложение, представленное на рис. 14.1. Для создания приложения потребуется выполнить следующие действия: 1. Запустите Visual Studio .NET (2003 или более позднюю версию) и выберите в качестве типа приложения C# Smart Device Application. 2. Выберите в качестве целевой платформы Pocket PC. (Для вас будет автоматически создан проект, и на экране появится окно конструктора форм Pocket PC.) 3. Добавьте в форму элемент управления Button. (Ему будет автоматически присвоено имя button1.) 4. Добавьте в форму элемент управления TextBox. (Ему будет автоматически присвоено имя textBox1.) 5. Установите для свойства MultiLine элемента управления TextBox значение true и измените размеры текстового окна таким образом, чтобы оно заняло почти всю форму. 6. Установите для свойства ScrollBar элемента управления TextBox значение vertical. 7. Дважды щелкните на элементе управления Button в окне конструктора форм и введите код функции button1_Click(), приведенный в листинге. 8. Введите весь оставшийся код, приведенный в листинге 14.1. 9. Вернитесь в окно конструктора форм. 10. Установите для свойства MinimizeBox формы значение false. Благодаря этому во время выполнения в верхней правой части формы появится кнопка OK, с помощью которой вы легко сможете закрыть форму и выйти из приложения. Эта возможность оказывается очень полезной при многократном тестировании приложения. 11. Запустите приложение и щелкните на кнопке Button; полученные вами результаты должны воспроизводить те, которые представлены на рис. 14.1. 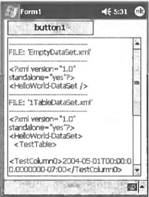 Рис. 14.1. Простой пример, демонстрирующий создание объекта ADO.NET DataSet Листинг 14.1. Простой пример создания и использования объекта ADO.NET DataSet //Объект DataSet, который мы собираемся загрузить System.Data.DataSet m_myDataSet; //Константы, которые будут использоваться const string FILE_EMPTY_DATASET = "EmptyDataSet.xml"; const string FILE_1TABLE_DATASET = "1TableDataSet.xml"; const string dividerLine = "-----------------------------\r\n"; const string nextLine = "\r\n"; //------------------------------------------------------- //Загрузить содержимое файла и присоединить его к тексту, //содержащемуся в элементе управления textBox1 //------------------------------------------------------- private void addFileContentsToTextBox(string fileName) { //Открыть файл и считать его содержимое System.IO.StreamReader myStreamReader; myStreamReader = System.IO.File.OpenText(fileName); string fileText = myStreamReader.ReadToEnd(); //Закрыть файл myStreamReader.Close(); //Присоединить содержимое к тексту, находящемуся в текстовом окне textBox1.Text = textBox1.Text + dividerLine + "FILE: '" + fileName + "'" + nextLine + dividerLine + fileText + nextLine; } //------------------------------------------------------- //1. Создает набор данных, // сохраняет набор данных в виде XML, // отображает результаты в текстовом окне //2. Добавляет таблицу данных в набор данных, // добавляет два типизированных столбца в таблицу данных, // добавляет две строки в таблицу данных, // сохраняет набор данных в виде XML, // отображает результаты в текстовом окне //------------------------------------------------------- private void button1_Click(object sender, System.EventArgs e) { //Очистить текстовое окно от содержимого textBox1.Text = ""; //=========================================== //1. Создать новый набор данных //=========================================== m_myDataSet = new System.Data.DataSet("HelloWorld-DataSet"); //Записать содержимое ADO.NET DataSet в виде XML и отобразить //файл в текстовом окне m_myDataSet.WriteXml(FILE_EMPTY_DATASET); addFileContentsToTextBox(FILE_EMPTY_DATASET); //================================================== //2. Добавить таблицу данных в набор данных ADO.NET, // а также 2 строки данных в таблицу данных //================================================== System.Data.DataTable myTestTable; myTestTable = m_myDataSet.Tables.Add("TestTable"); //---------------------------- //Добавить 2 столбца в таблицу //---------------------------- //Добавить столбец данных в таблицу DataTable набора DataSet myTestTable.Columns.Add("TestColumn0", typeof(System.DateTime)); //Добавить строковый столбец в таблицу DataTable набора DataSet myTestTable.Columns.Add("TestColumn1", typeof(string)); //-------------------------------- //Добавить строки данных в таблицу //-------------------------------- //Добавить строку данных в таблицу данных object[] rowOfData; rowOfData = new object[2]; //Столбец 0 — это тип даты rowOfData[0] = System.DateTime.Today; //Столбец 1 — это строковый тип rowOfData[1] = "а string of data today"; myTestTable.Rows.Add(rowOfData); //Добавить вторую строку данных в таблицу данных object[] rowOfData2; rowOfData2 = new object[2]; //Столбец 0 — это тип даты rowOfData2[0] = System.DateTime.Today.AddDays(1); //Столбец 1 — это строковый тип rowOfData2[1] = "tomorrow's string"; myTestTable.Rows.Add(rowOfData2); //Записать содержимое набора ADO.NET DataSet в виде XML и отобразить //файл в текстовом окне m_myDataSet.WriteXml(FILE_1TABLE_DATASET); addFileContentsToTextBox(FILE_1TABLE_DATASET); } //Конец функции Отслеживание изменения данныхОбъекты ADO.NET DataSet автоматически отслеживают изменения, вносимые в содержащиеся в них данные, включая создание, удаление и изменение строк данных в таблицах данных. Затем эти изменения могут быть приняты или отвергнуты, а принятые изменения переданы в базу данных в соответствии с необходимостью. Если источник данных рассредоточен по нескольким базам данных, то возможно даже обновление данных с использованием распределенных транзакций. Важно понимать, что объектам ADO.NET DataSet ничего не известно о базах данных, в которых данные хранятся постоянно; для восполнения этого пробела используются классы DataAdapter. Класс ADO.NET DataAdapter предназначен для перемещения данных между объектами ADO.NET DataSet и долговременными хранилищами. Все классы ADO.NET DataAdapter состоят из пользовательского кода; любая логика, необходимая для подключения к источнику данных, с которым ведется работа, получения этих данных и их обновления, пишется разработчиком. По сути дела, объекты ADO.NET DataSet представляют собой небольшие базы данных в памяти, и классы DataAdapter пишутся для того, чтобы обеспечить синхронизацию данных DataSet с базой данных; находится ли эта база данных на устройстве или на сервере, известно лишь коду адаптера данных (data adapter). Объекты DataAdapter могут существовать либо на стороне клиента, либо на стороне сервера. Если адаптер данных находится на сервере, то для предоставления ему данных объекта ADO.NET DataSet их копия должна быть передана с клиента на сервер. Обычно передача набора данных DataSet с клиента на сервер осуществляется путем сериализации объекта DataSet в XML, передачи его на сервер и последующей реконструкции DataSet из XML. Для всего этого в ADO.NET предусмотрена встроенная поддержка. Данная модель хорошо приспособлена для работы с Web-службами. Во многих случаях желательно избавить клиента от необходимости знать что-либо о конечных базах данных, к которым осуществляется доступ; это позволяет упростить архитектуру приложения за счет централизации доступа к базе данных на сервере. В подобных случаях данные объекта ADO.NET DataSet обычно передаются с клиентского устройства Web-службе, выполняющейся на сервере. Web-служба повторно загружает XML-данные в объект ADO.NET DataSet, а затем передает их в адаптер данных ADO NET, который и выполняет все необходимые обновления на сервере. Следует отметить, что объекты ADO.NET DataSet обладают такими встроенными механизмами, которые позволяют передавать на сервер лишь те данные DataSet, которые претерпели изменения (так называемые "диффграммы" ("diffgram"), или диаграммы отличий), это избавляет от необходимости перемещения полностью всех данных, содержащихся в DataSet, если изменились только несколько строк. Две модели использования ADO.NETADO.NET предлагает многоуровневый подход для работы с данными, что дает возможность выбрать тот уровень программной абстракции, который в наилучшей степени соответствует потребностям вашего мобильного приложения и требованиям производительности. Высокоуровневый подход, основанный на использовании объектов ADO.NET DataSetНа самом высоком уровне абстракции доступа к данным платформа .NET Compact Framework предлагает наряду с объектами ADO.NET DataSet также объекты DataTable и DataView. Схема различных логических связей для приложений такого рода представлены на рис. 14.2. Как обсуждалось выше, центральное место в этой модели занимают объекты ADO NET DataSet. 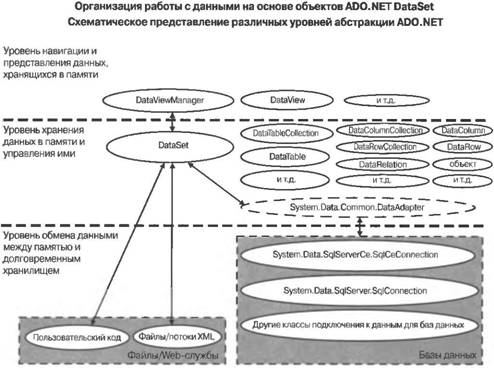 Рис. 14.2. Подход к организации работы с данными, основанный на использовании объектов ADO.NET DataSet Низкоуровневый подход, основанный на использовании объектов подключения к данным ADO.NET Хотя объекты ADO.NET DataSet и предлагают необычайно широкие возможности для работы с данными, создание дополнительных объектов для абстрагирования и управления данными приложения и отношениями между ними приводит к увеличению накладных расходов. Иногда эти накладные расходы оказываются недопустимо высокими или нежелательными; в подобных случаях следует подумать об использовании альтернативного низкоуровневого варианта. Альтернативный подход, в котором используются низкоуровневые абстракции ADO.NET, проиллюстрирован на рис. 14.3. В основе этого подхода лежит создание пользовательской модели управления данными поверх объектов подключения к данным (data connection objects), предоставляемых поставщиками данных (data providers) ADO.NET. Так, для обеспечения доступа к собственной базе данных SQL Server предлагает класс System.Data.SqlClient.SqlConnection, тогда как SQL СЕ для тех же целей предоставляет класс System.Data.SqlServerCe.SqlCeConnection. Обычно эти классы используются совместно с классами DataAdapter для обмена данными с объектами DataSet, но могут использоваться и сами по себе для получения и передачи данных с использованием ваших собственных форматов данных. Эта модель может обеспечить значительную экономию памяти, если мобильное приложение не нуждается в тех широких возможностях в отношении доступа к данным, которые предлагает универсальная модель на основе объектов ADO.NET DataSet. Схема различных взаимосвязей, соответствующая данному случаю, представлена на рис. 14.3. В случае выбора низкоуровневого подхода ваше приложение берет на себя непосредственную ответственность за управление данными, загружаемыми в память, отслеживание любых изменений, вносимых в данные, и передачу этих изменений обратно в долговременное хранилище в соответствии с необходимостью. Снижение накладных расходов при работе на более низком уровне абстракции достигается за счет повышения ответственности разработчика за проектирование и поддержание эффективной модели данных. 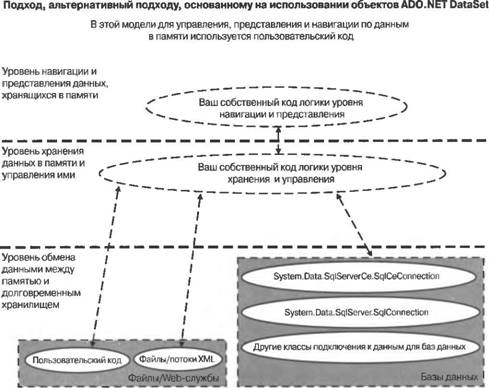 Рис. 14.3. Альтернатива использованию объектов ADO.NET DataSet Модель программирования, основанная на использовании объектов ADO.NET DataSet, предоставляет замечательные возможности для работы с реляционными данными, однако ее применение уместно не в любом контексте. Важно понимать, когда следует использовать ADO.NET для удовлетворения потребностей приложения в доступе к данным, а когда — не следует. В каких случаях следует использовать объекты ADO.NET DataSetОбъекты ADO.NET DataSet следует использовать в тех случаях, когда приложению требуются широкие возможности манипулирования данными в памяти или когда возникает необходимость в использовании сложного реляционного способа прослеживания данных. Поскольку, по существу, ADO.NET поддерживает для вас в памяти небольшую реляционную базу данных, которая отслеживает вносимые изменения, то использование этого протокола предоставляет широкие возможности для автоматического управления набором в высшей степени динамичных данных, а также навигации по связям между отдельными порциями данных. Объекты ADO.NET DataSet оказываются удобными в тех случаях, когда 1) объем данных, с которыми вы должны работать, не слишком велик по сравнению с емкостью памяти мобильного устройства, и 2) данные имеют динамическую природу, что диктует необходимость отслеживания и распространения изменений. Объекты ADO.NET DataSet обеспечивают обмен данными с долговременным хранилищем. Такой обмен осуществляется одним из трех способов: 1) использование классов DataAdapter, осуществляющих соединение с базами данных посредством объектов подключения к данным, 2) сериализация объектов DataSet в файлы и потоки XML и наоборот, и 3) сериализация посредством пользовательского кода, который считывает данные из объектов DataSet или помещает данные в указанные объекты. Краткие описания каждого из упомянутых способов передачи данных приводятся ниже. Использование классов DataAdapter для организации взаимодействия с базами данныхТип ADO.NET System.Data.Common.DataAdapter — это абстрактный класс, то есть он предоставляет шаблон для порождения других классов DataAdapter, специфических по отношению к базе данных, которые, собственно говоря, и используются. Вместе с .NET Compact Framework поставляются два адаптера данных: 1. SqlDataAdapter. Класс System.Data.SqlClient.SqlDataAdapter используется при работе с базами данных SQL Server, выполняющимися на серверах. 2. SqlCeDataAdapter. Класс System.Data.SqlServerCe.SqlCeDataAdapter используется при работе с базами данных SQL СЕ, выполняющимися на мобильных устройствах. Для подключения к другим источникам данных могут использоваться адаптеры данных, предлагаемые сторонними производителями. Кроме того, вы можете написать собственный класс DataAdapter, если имеется пользовательский источник данных, к которому вы хотите подключиться. Независимо от выбранного вами типа адаптера данных объекты DataAdapter работают посредством присоединенных к ним объектов Command. В отличие от класса DataAdapter у класса Command нет корневого класса, от которого могли бы быть произведены другие классы Command, специфические по отношению к базам данных; понятие класса Command существует лишь как понятие, которое используется при работе с различными адаптерами данных. Для объектов SqlDataAdapter существуют связанные с ними объекты SqlCommand, для объектов SQL СЕ SqlCeDataAdapter — объекты SqlCeCommand, и так далее. В свою очередь, с объектами Command связываются объекты Connection, которые отображают команды (commands) на конкретный экземпляр той или иной базы данных; например, для выполнения команд при работе через конкретное соединение с базой данных SQL Server объект SqlCommand будет использовать объект SqlConnection. Указанные объекты Command исполняют запросы и другие команды баз данных, которые должны выполняться для извлечения данных из баз данных или помещения их в базы данных, используемые вашим приложением. Объектам Command известно, как осуществлять те или иные действия при работе с той или иной базой данных, когда они выполняют SQL-команды для выборки, обновления, вставки или удаления данных. Так, для выполнения этих команд у класса SQLDataAdapter имеются следующие четыре свойства: SelectCommand, UpdateCommand, InsertCommand и DeleteCommand. Каждое из этих свойств имеет тип SqlCommand. Аналогичным образом, у объекта SqlCeDataAdapter также имеются четыре свойства с теми же именами, но типом этих свойств является SQLCeCommand. Краткое подведение итогов. Адаптеры данных играют роль посредников при осуществлении связи между объектами ADO.NET DataSet и базами данных. Как правило, для выполнения этих функций адаптеры данных используют объекты Command. Объекты Command являются специфическими по отношению к каждому типу баз данных. В свою очередь, объекты Command обычно ассоциируются с объектами Connection, владеющими соединениями с конкретным сервером. В типичных случаях объект Command является владельцем таких SQL-операторов, как Select * from Customers, а объекты Connection — владельцами логического соединения с базой данных, через которое им передаются эти команды. При создании .NET-приложений для настольных компьютеров и серверов Visual Studio .NET предлагает инструментальные средства времени проектирования, которые облегчают настройку конфигураций адаптеров данных и ассоциированных с ними классов Command; это значительно упрощает процесс доступа к базам данных. В отличие от этого, для создания и использования адаптера данных в .NET Compact Framework вы должны сами написать код, обеспечивающий конфигурирование объектов DataAdapter и Command для работы с используемыми вами источниками данных. Возможно, в будущем автоматизированные средства будут поддерживать также .NET Compact Framework и объекты DataAdapter и DataCommand для работы с популярными базами данных, но пока что вы можете полагаться только на самих себя. Поскольку предусмотренные для настольных компьютеров и серверов инструментальные средства для работы с базами данных автоматически генерируют исходный код для приложений, часто имеет смысл воспользоваться сгенерированным ими кодом и адаптировать его для выполнения на мобильных устройствах; хотя этот код и будет существенно отличаться от того, что вам нужно, он послужит вам неплохой отправной точкой. Использование файлов и потоков XML для сохранения и передачи данныхСохранение содержимого объектов ADO.NET DataSet в виде XML-файлов можно считать вариантом "базы данных для бедных". Данные приложения сохраняются в текстовом файле с использованием формата, который позволяет осуществить последующую повторную загрузку данных в память в виде объекта ADO.NET DataSet. Это аналогично получению объекта DataSet, возвращаемого через запрос Web-службы. В противоположность сохранению данных в базе данных использование текстового XML-файла для хранения данных лишает ваше приложение богатых возможностей транзакций и гарантий целостности данных, предлагаемых современными базами данных. Несмотря на ограниченность этой модели в отношении хранения больших объемов данных и возможности обновления данных посредством механизма транзакций, она может хорошо послужить при хранении данных небольшого объема (например, XML-файлы размером 20 Кбайт) или при перемещении данных на сервер посредством XML-потоков. Сохранение объектов DataSet в виде постоянно существующих XML-файлов можно рассматривать как простой способ упаковки небольших или средних объемов информации о состояния приложения для ее последующего повторного использования. При записи содержимого объекта DataSet в файл или поток XML важно внимательно изучить опции, предлагаемые перечислением System.Data.XmlWriteMode. Исходя из соображений производительности, при сохранении объектов DataSet в виде постоянно существующих XML-файлов рекомендуется одновременно сохранять XML-схему (то есть использовать System.Data.XmlWriteMode.WriteSchema). Запись схемы данных вместе с самими данными обеспечивает существенное ускорение повторной загрузки XML-данных в объект DataSet; в противном случае схема должна будет динамически определяться во время повторной загрузки данных, а это потребует выполнения дополнительной работы. В листинге 14.2 представлен простой пример сохранения объекта DataSet в XML-файле. В этом примере предоставляется возможность задавать параметр WriteSchema. Чтобы выполнить пример, дополните код, приведенный в листинге 14.1, кодом из листинга 14.2 и добавьте элемент управления Button, который вызывает функцию writeDataSetToFile. Листинг 14.2. Использование параметра XMLWriteMode при сохранении объекта ADO.NET DataSet//----------------------------------------------------------------------- //Необходимость в этой функции возникает по той причине, что .NET Compact //Framework не поддерживает перегрузку: // //"public void WriteXml(string, XmlWriteMode);" // //в качестве функции-члена "public" (только "private") //----------------------------------------------------------------------- void writeDataSetToFile(System.Data.DataSet ds, string filename, System.Data.XmlWriteMode xmlWriteMode) { //Создать объект XmlWriter для записи наших XML-данных System.Xml.XmlWriter xmlWriter; xmlWriter = new System.Xml.XmlTextWriter(filename, System.Text.Encoding.Default); //ПРИМЕЧАНИЕ: Эта перегруженная версия не является общедоступной (public)! //ds.WriteXml(filename, xmlWriteMode); //Вместо этого используем следующую функцию: ds.WriteXml(xmlWriter, xmlWriteMode); xmlWriter.Close(); //Важно закрыть файл! }Сериализация объектов ADO.NET DataSet с помощью пользовательского кода Как ранее уже обсуждалось, объекты ADO.NET DataSet обладают встроенной поддержкой сохранения содержимого в виде XML-файлов. В то же время, этот XML-формат не является произвольным и должен соответствовать определенной схеме XML, предназначенной специально для использования с объектами ADO.NET DataSet. Если вашему приложению необходимо выполнять запись или считывание информации с использованием другой схемы XML или любого другого формата, то для этого вы должны сами написать код соответствующей пользовательской логики. Модель, основанная на использовании объектов DataSet, обладает достаточной гибкостью для того, чтобы обеспечить поддержку сохранения данных в любом желаемом виде. Поскольку объекты ADO.NET DataSet поддерживают в памяти простую базу данных, не зависящую от формата хранения, вы можете сохранить этот объект в любом формате (например, в пользовательском формате XML, двоичном, простом текстовом), который отвечает вашим потребностям. Следует лишь отметить, что прежде чем взваливать на себя дополнительную работу по проектированию, необходимо убедиться в том, что для этого имеются серьезные основания. Если вы пишете пользовательский код десериализации для заполнения данными объекта DataSet, то код вашего приложения должен программным путем построить таблицы, столбцы и определения отношений, а затем заполнить таблицы импортируемыми данными. Аналогичным образом, при пользовательском сохранении объекта DataSet логика вашего приложения должна обеспечить итерирование по всем таблицам и сохранение данных с использованием любого желаемого механизма. Для чтения и записи данных с использованием нескольких различных источников можно привлечь гибридную модель; например, объект DataSet может автоматически заполняться данными при помощи объекта SQLDataAdapter, подключенного к базе данных SQL, а впоследствии эти данные могут быть сериализованы с применением пользовательского формата, локального для устройства. Объектам ADO.NET DataSet безразлично, каким именно образом данные были в них помещены и откуда они поступили. Работа с нетипизированными объектами DataSetВ .NET Framework для настольных компьютеров и серверов предлагается концепция "типизированных объектов DataSet". Типизированный объект DataSet — это строго типизированный набор интерфейсных классов, реализованных посредством механизма наследования поверх объектов DataSet, DataTable и других объектов данных ADO.NET. Такие унаследованные классы обеспечивают доступ к базовым таблицам и строкам объектов DataSet с использованием строго типизированных членов класса, имена которых совпадают с именами обрабатываемых таблиц и столбцов. Например, вместо того чтобы осуществлять поиск столбцов по именам в соответствии с поздним связыванием (например, myDataRow["CustomerFirstName"]) или требовать использования индексов столбцов (myDataRow[2]), разработчик может использовать раннее связывание свойства (myDataRow.CustomerFirstName). Именно такое связывание на стадии проектирования и есть то, что делает объект DataSet "типизированным". Исходный код для типизированных классов DataSet автоматически генерируется средой времени проектирования Visual Studio .NET.
.NET Compact Framework не поддерживает компиляцию кода типизированных объектов DataSet, автоматически сгенерированного для настольных компьютеров, Это означает, что наиболее распространенным методом работы с объектами ADO.NET DataSet с использованием .NET Compact Framework является работа непосредственно с нетипизированным классом DataSet и подчиненными ему классами DataTable, DataColumn и DataRow. Кроме некоторого усложнения вашего кода и необходимости внимательно следить за тем, чтобы не допустить опечаток в именах столбцов и полей (распространенная ошибка), использование нетипизированных объектов DataSets не обладает никакими другими недостатками. Наиболее высокая производительность достигается тогда, когда вы работаете с нетипизированными классами непосредственно, а не через какие-либо интерфейсные уровни. Перенос типизированных объектов ADO.NET DataSet на мобильные устройстваМеры по обеспечению максимальной производительности при работе с объектами ADO.NET DataSet При работе с объектами DataSet очень важно не забывать об эффективности кода. Почти с одинаковой легкостью можно написать как эффективный код, так и код, производительность которого будет крайне низка. Распространенной ошибкой разработчиков, приводящей к низкой производительности кода, является поиск таблиц и столбцов по их строковым именам, а не при помощи более эффективных механизмов индексирования. Этот момент приобретает еще большее значение при доступе к полям строк данных, поскольку эта операция часто выполняется в итерационных циклах, включающих значительное количество строк. Обращение к отдельным элементам при осуществлении такого доступа может осуществляться тремя способами, перечисленными ниже в порядке, соответствующем увеличению производительности: 1. Поиск полей с использованием строковых имен. Например: myRow["myColumnName"]; этот способ является самым медленным, поскольку для нахождения нужного поля строка имени искомого столбца должна сравниваться со всеми имеющимися именами столбцов. 2. Поиск полей с использованием целочисленных индексов. Например: myRow[2]; Ввиду использования целых чисел этот способ представляет собой определенное улучшение по сравнению с поиском по строковым именам. Чтобы использовать этот механизм, ваш код должен организовать предварительный просмотр и кэширование целочисленных индексов столбцов 3. Поиск полей, с использованием объектов столбцов. Например: myRow[myColumnObject], где myColumnObject представляет объект типа System.Data.DataColumn. Этот способ обеспечивает значительное улучшение производительности по сравнению с обоими предыдущими механизмами. Чтобы использовать этот механизм, ваш код должен кэшировать объект столбца (column object), который представляет интересующее вас поле. В листинге 14.3 приведен код, который позволяет тестировать производительность трех различных подходов, описанных выше. Этот код имитирует типичную задачу обработки данных, включающую поиск и изменение записей. Вычисления соответствуют описанному ниже сценарию. Агенты транспортной компании, работающие на выезде, используют мобильные устройства для внесения изменений в информацию о маршруте следования клиентов. В силу внезапного изменения погодных условий, например из-за снегопада, возникает необходимость во внесении изменений в маршрут следования группы пассажиров, дожидающихся отправки на вокзале или в аэропорте или находящихся в данный момент в движущемся поезде или на борту самолета. Требуется обновить информацию о пунктах пересадки пассажиров и пересмотреть маршруты следования. Простейший способ решения этой задачи состоит в том, чтобы вооружить сотрудников транспортной компании мобильными устройствами, в которых содержится информация о маршрутах движения транспортных средств. При наличии соответствующего мобильного приложения несколько агентов могут выйти к клиентам и решить их проблемы, избавляя их от необходимости стоять в очереди, причем во многих случаях можно успеть полностью оформить все необходимые проездные документы еще до окончания текущего рейса поезда или самолета. В мобильных устройствах содержится загруженный список клиентов и подробная информация о маршрутах их следования. Чтобы ускорить процесс поиска соответствующих записей и уменьшить вероятность ошибок, мобильные устройства оборудованы устройствами для считывания номера кредитной карточки пассажира, который используется в качестве ключа для проведения соответствующего поиска. После того как запись о клиенте будет найдена, сведения о его маршруте могут быть обновлены с учетом новой информации. В нашем тестовом коде применяется упрощенная версия этого сценария, и в таблице данных будут содержаться только имя клиента, дата рейса и номер кредитной карточки. Разумеется, в действительности приходится осуществлять доступ к гораздо более многочисленным данным, но в нашем упрощенном варианте все основные составляющие задачи учтены, есть данные, хранящиеся на устройстве, и мы должны иметь возможность производить среди них поиск и вносить изменения. Поскольку для реальных сценариев характерно выполнение значительно большего числа операций поиска, их производительность может быть оценена путем экстраполяции результатов выполнения нашего тестового приложения. В табл. 14 1 представлены результаты выполнения теста на физическом устройстве Pocket PC. Как и следовало ожидать, поиск по текстовому содержимому (столбец А) оказался самым медленным и потребовал 32,82 секунды. Поиск с использованием целочисленного индекса (столбец Б) привел к вполне ощутимому улучшению результатов на 8% и потребовал 30,28 секунд. Поиск с использованием объектов DataColumn (столбец В) принес 28%-ное улучшение по сравнению с текстовым поиском. Выигрыш довольно значительный и явно свидетельствует в пользу кэширования объектов DataColumn при выполнении циклических операций поиска данных в таблицах данных. Таблица 14.1 Производительность тестового приложения при выполнении 500 итераций с использованием 201 строки данных на физическом устройстве Pocket PC
Приведенный в листинге 14.3 код необходимо включить в форму в проекте Pocket PC. Для создания и выполнения приложения потребуется выполнить следующие действия. 1. Запустите Visual Studio .NET (2003 или более позднюю версию) и выберите в качестве типа приложения C# Smart Device Application. 2. Выберите в качестве целевой платформы Pocket PC. (Для вас будет автоматически создан проект, и на экране появится окно конструктора форм Pocket PC.) 3. Добавьте в форму элемент управления Button. Присвойте ему имя buttonRunTest. 4. Дважды щелкните на элементе управления Button в окне конструктора форм. В автоматически сгенерированной и подключенной функции обработчика событий введите код функции buttonRunTest_Click() из листинга 14.3. 5. Введите весь оставшийся код в тот же класс. 6. Установите для свойства MinimizeBox формы значение false. Благодаря этому во время выполнения в верхней правой части формы появится кнопка OK, с помощью которой вы легко сможете закрыть форму и выйти из приложения. Эта возможность оказывается очень полезной при многократном тестировании приложения. 7. Запустите приложение, нажав клавишу <F5>. Для запуска всех трех вариантов тестирования на выполнение следует щелкать на кнопке. После каждого прогона приложения должно появляться окно сообщений, содержащее результаты тестирования. Листинг 14.3. Сравнение производительности различных вариантов доступа к данным с использованием объектов DataSetSystem.Data.DataSet m_myDataSet; //Объект Dataset для теста //Индексы столбцов и таблицы, подлежащие кэшированию private bool m_indexesLookedUp = false; private const int INVALID_INDEX = -1; private int m_IndexOfTestColumn_CreditCard = INVALID_INDEX; private int m_IndexOfTestColumn_TravelDate = INVALID_INDEX; private int m_IndexOfTestTable = INVALID_INDEX; //Столбцы данных и таблица, подлежащие кэшированию System.Data.DataColumn m_TestColumn_CreditCard; System.Data.DataColumn m_TestColumn_TravelDate; private System.Data.DataTable m_TableCustomerInfo; //3 вида тестов, которые мы можем выполнять public enum testType { textColumnLookup, cachedIndexLookup, cachedColumnObject } //Эти константы определяют размерные характеристики тестов const int DUMMY_ROWS_OF_DATA = 100; const int NUMBER_TEST_ITERATIONS = 500; //Табличная информация const string TABLE_NAME_PASSENGERINFO = "CustomerTravelInfo"; const string COLUMN_NAME_DATE_OF_TRAVEL = "DateOfTravel"; const string COLUMN_NAME_PASSENGER_NAME = "PassengerName"; const string COLUMN_NAME_PASSENGER_CREDIT_CARD = "PassengerCreditCard"; const string TEST_CREDIT_CARD = "IvoCard-987-654-321-000"; //-------------------- //Создает набор данных //-------------------- private void createDataSet() { //1. Создать новый объект DataSet m_myDataSet = new System.Data.DataSet("TravelService Dataset"); //2. Добавить объект DataTable в объект ADO.NET DataSet System.Data.DataTable myTestTable; myTestTable = m_myDataSet.Tables.Add(TABLE_NAME _PASSENGERINFO); //Добавить 2 столбца в таблицу //Добавить столбец данных в таблицу DataTable набора данных DataSet myTestTable.Columns.Add(COLUMN_NAME_DATE_OF_TRAVEL,typeof(System.DateTime)); //Добавить столбец строк в таблицу DataTable набора данных DataSet myTestTable.Columns.Add(COLUMN_NAME_PASSENGER NAME,typeof(string)); //Добавить столбец строк в таблицу DataTable набора данных DataSet myTestTable.Columns.Add(COLUMN_NAME_PASSENGER_CREDIT_CARD,typeof(string)); //Данные для размещения в строках данных object[] objArray; objArray = new object[3]; //-------------------------------- //Добавить строки данных в таблицу //-------------------------------- System.Text.StringBuilder buildTestString; buildTestString = new System.Text.StringBuilder(); for (int addItemsCount = 0; addItemsCount < DUMMY_ROWS_OF_DATA; addItemsCount++) { //Выбрать день отъезда пассажира objArray[0] = System.DateTime.Today.AddDays(addItemsCount); //Выбрать имя пассажира buildTestString.Length = 0; buildTestString.Append("TestPersonName"); buildTestString.Append(addItemsCount); objArray[1] = buildTestString.ToString(); //Связать с пассажиром текстовый номер кредитной карточки buildTestString.Length = 0; buildTestString.Append("IvoCard-000-000-0000-"); buildTestString.Append(addItemsCount); objArray[2] = buildTestString.ToString(); //Добавить элементы массива в строку набора данных myTestTable.Rows.Add(objArray); } //Добавить элемент, поиск которого мы хотим проводить при выполнении теста objArray[0] = System.DateTime.Today; objArray[1] = "Ms. TestPerson"; objArray[2] = TEST_CREDIT_CARD; //Добавить элементы массива в строку набора данных myTestTable.Rows.Add(objArray); } //Конец функции //--------------------------------------------------------------- //Найти и кэшировать все индексы набора данных, которые нам нужны //--------------------------------------------------------------- private void cacheDataSetInfo() { //Выйти из функции, если индексы уже загружены if (m_indexesLookedUp == true) { return; } //Кэшировать индекс таблицы m_IndexOfTestTable = m_myDataSet.Tables.IndexOf(TABLE_NAME_PASSENGERINFO); //------------------------------------------ //Итерировать по всем столбцам нашей таблицы //и кэшировать индексы нужных столбцов //------------------------------------------ m_TableCustomerInfo = m_myDataSet.Tables[m_IndexOfTestTable]; int dataColumnCount = m_TableCustomerInfo.Columns.Count; System.Data.DataColumn myColumn; for (int colIdx = 0; colIdx < dataColumnCount;) { myColumn = m_TableCustomerInfo.Columns[colIdx]; //Предпринимать поиск, только если это еще не сделано if (m_IndexOfTestColumn_CreditCard == INVALID_INDEX) { //Проверить, совпадает ли имя if (myColumn.ColumnName == COLUMN_NAME_PASSENGER_CREDIT_CARD) { //Кэшировать индекс m_IndexOfTestColumn_CreditCard = colIdx; //Кэшировать столбец m_TestColumn_CreditCard = myColumn; goto next_loop_iteration; //Опустить другие операции сравнения... } //Endif: сравнение строк } //Endif if (m_IndexOfTestColumn_TravelDate == INVALID_INDEX) { //Проверить, совпадает ли имя if (myColumn.ColumnName == COLUMN_NAME_DATE_OF_TRAVEL) { //Кэшировать индекс m_IndexOfTestColumn_TravelDate = colIdx; //Кэшировать столбец m_TestColumn_TravelDate = myColumn; goto next_loop_iteration; //Опустить другие операции сравнения. } //Endif: сравнение строк } //Endif next_loop_iteration: colIdx++; } m_indexesLookedUp =true; } //-------------- //Выполнить тест //-------------- void changeDayOfTravel_test(testType kindOfTest) { //Отобразить курсор ожидания System.Windows.Forms.Cursor.Current = System.Windows.Forms.Cursors.WaitCursor; //Начать с известной даты... System.DateTime newDate; newDate = System.DateTime.Today; changeDayOfTravel_textColumnLookup(ТЕST_CREDIT_CARD, newDate); //ДОПУСТИМО ТОЛЬКО ДЛЯ ТЕСТОВОГО КОДА!!! //Вызов сборщика мусора в коде ЗАМЕДЛИТ работу вашего приложения! System.GC.Collect(); const int testNumber = 0; //Настроить соответствующим образом в зависимости от вида выполняемого теста switch (kindOfTest) { case testType.textColumnLookup: PerformanceSampling.StartSample(testNumber, "Text based Column lookup."); break; case testType.cachedIndexLookup: PerformanceSampling.StartSample(testNumber, "Cached Column Index lookup."); break; case testType.cachedColumnObject: PerformanceSampling.StartSample(testNumber, "Cached Column objects"); break; default: throw new Exception("Unknown state!"); } //Выполнить тест! for (int testCount = 0; testCount < NUMBER_TEST_ITERATIONS; testCount++) { //Передвинуть дату вперед на один день newDate = newDate.AddDays(1); int numberRecordsChanged = 0; //Какой вид теста мы выполняем? switch (kindOfTest) { case testType.textColumnLookup: //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Просмотреть все имена, используя СТРОКИ numberRecordsChanged = changeDayOfTravel_textColumnLookup(ТЕST_CREDIT_CARD, newDate); break; case testType.cachedIndexLookup: //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированные индексы numberRecordsChanged = changeDayOfTravel_cachedColumnIndex(ТЕST_CREDIT_CARD, newDate); break; case testType.cachedColumnObject: //НАИЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированные объекты //столбцов numberRecordsChanged = changeDayOfTravel_CachedColumns(TEST_CREDIT_CARD, newDate); break; } //Убедиться в том, что тест выполняется, как и ожидалось... if (numberRecordsChanged != 1) { System.Windows.Forms.MessageBox.Show("No matching records found. Test aborted!"); return; } } //Получить время, которое потребовалось для выполнения теста PerformanceSampling.StopSample(testNumber); //Обычный курсор System.Windows.Forms.Cursor.Current = System.Windows.Forms.Cursors.Default; //Отобразить результаты выполнения теста string runInfo = NUMBER_TEST_ITERATIONS.ToString() + "x" + DUMMY_ROWS_OF_DATA.ToString() + ": "; System.Windows.Forms.MessageBox.Show(runInfo + PerformanceSampling.GetSampleDurationText(testNumber)); } //ФУНКЦИЯ ПОИСКА, ОБЛАДАЮЩАЯ НИЗКОЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ private int changeDayOfTravel_ textColumnLookup(string creditCardNumber, System.DateTime newTravelDate) { int numberRecordsChanged = 0; //Найти имя таблицы System.Data.DataTable dataTable_Customers; //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Осуществить поиск в таблице, используя //сравнение строк! dataTable_Customers = m_myDataSet.Tables[TABLE_NAME_PASSENGERINFO]; foreach (System.Data.DataRow currentCustomerRow in dataTable_Customers.Rows) { string currentCreditCard; //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Осуществить поиск в таблице, используя //сравнение строк! currentCreditCard = (string)currentCustomerRow[COLUMN_NAME_PASSENGER_CREDIT_CARD]; //Проверить, является ли данная кредитная карточка искомой if (creditCardNumber == currentCreditCard) { //Изменить дату отъезда //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Осуществить поиск столбца, используя //сравнение строк! System.DateTime currentTravelDate = (System.DateTime)currentCustomerRow[COLUMN_NAME_DATE_OF_TRAVEL]; if (currentTravelDate != newTravelDate) { //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Осуществить поиск столбца, используя //сравнение строк! currentCustomerRow[COLUMN_NAME_DATE_OF_TRAVEL] = newTravelDate; numberRecordsChanged++; } } //endif: сравнение строк } //end foreach return numberRecordsChanged; //Количество обновленных записей } //ФУНКЦИЯ, ХАРАКТЕРИЗУЮЩАЯСЯ НЕСКОЛЬКО ЛУЧШЕЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ private int changeDayOfTravel_cachedColumnIndex(string creditCardNumber, System.DateTime newTravelDate) { int numberRecordsChanged = 0; //Поиск имени таблицы System.Data.DataTable dataTable_Customers; //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: использовать кэшированный индекс dataTable_Customers = m_myDataSet.Tables[m_IndexOfTestTable]; foreach (System.Data.DataRow currentCustomerRow in dataTable_Customers.Rows) { string currentCreditCard; //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: использовать кэшированный индекс столбца! currentCreditCard = (string)currentCustomerRow[m_IndexOfTestColumn_CreditCard]; //Проверить, совпадает ли номер кредитной карточки... if (creditCardNumber == currentCreditCard) { //Изменить дату отъезда //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированный индекс столбца! System.DateTime currentTravelDate = (System.DateTime)currentCustomerRow[m_IndexOfTestColumn_TravelDate]; if (currentTravelDate != newTravelDate) { //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированный индекс //столбца! currentCustomerRow[m_IndexOfTestColumn_TravelDate] = newTravelDate; numberRecordsChanged++; } } } return numberRecordsChanged; //Количество обновленных записей } //ФУНКЦИЯ, ОБЛАДАЮЩАЯ НАИЛУЧШЕЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ private int changeDayOfTravel_CachedColumns(string creditCardNumber, System.DateTime newTravelDate) { int numberRecordsChanged = 0; //Найти имя таблицы System.Data.DataTable dataTable_Customers = m_TableCustomerInfo; foreach (System.Data.DataRow currentCustomerRow in dataTable_Customers.Rows) { string currentCreditCard; //НАИЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированный индекс столбца! currentCreditCard = (string)currentCustomerRow[m_TestColumn CreditCard]; //Проверить, совпадает ли номер кредитной карточки... if (creditCardNumber == currentCreditCard) { //Изменить дату отъезда //НАИЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированный индекс столбца! System.DateTime currentTravelDate = (System.DateTime)currentCustomerRow[m_TestColumn_TravelDate]; if (currentTravelDate != newTravelDate) { //НАИЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать кэшированный индекс //столбца! currentCustomerRow[m_TestColumn TravelDate] = newTravelDate; numberRecordsChanged++; } } } return numberRecordsChanged; //Количество обновленных записей } //Событие щелчка на кнопке private void buttonRunTest_Click(object sender, System.EventArgs e) { createDataSet(); cacheDataSetInfo(); //НИЗКАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать поиск по строкам changeDayOfTravel_test(testType.textColumnLookup); //ЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать поиск по целочисленным индексам changeDayOfTravel_test(testType.cachedIndexLookup); //НАИЛУЧШАЯ ПРОИЗВОДИТЕЛЬНОСТЬ: Использовать поиск по объектам столбцов changeDayOfTravel_test(testType.cachedColumnObject); }В каких случаях не следует использовать объекты ADO.NET DataSet Если данные мобильного приложения большей частью применяются только для чтения, если приходится хранить большие объемы данных в памяти или если между данными существуют сравнительно простые отношения, то стоит подумать о привлечении пользовательской модели управления данными. Объекты ADO.NET DataSet можно эффективно реализовать, но предлагаемая ими модель управления данными является универсальной. Можно добиться существенного выигрыша в объеме занимаемой памяти и производительности, создав специализированную модель данных, которая наилучшим образом соответствует вашим потребностям. Ключевым фактором эффективного использования памяти является уменьшение количества объектов, которые должны размещаться для хранения ваших данных; как правило, чем меньше объектов, тем меньше нагрузка на память и тем выше производительность. В табл. 14.2 и листинге 14.4 представлены результаты использования оптимизированного пользовательского формата для хранения строк данных. Тестовый код, приведенный в листинге 14.4, выполняет ту же задачу, что и код из листинга 14.3, но вместо объектов ADO.NET DataSet в нем используется простой типизированный массив данных. От такой замены производительность приложения выигрывает в двух отношениях: 1. Быстродействие. Как видно из табл. 14.2, применение пользовательского формата данных позволило уменьшить время выполнения приложения до 38% того времени, которое было зафиксировано для решения, базирующегося на ADO.NET с использованием текстового индекса. Сравнение с результатом, достигнутым в оптимизированном варианте поиска, в котором использовался объект DataColumn, свидетельствует о сокращении времени выполнения почти в два раза (12,32/23,54=52,3%). 2. Снижение нагрузки на память. Поскольку в решении, основанном на пользовательском формате данных, для хранения данных требуется лишь минимальное количество объектов, а накладные расходы, связанные с объектами ADO.NET DataSet, отсутствуют, наше приложение предъявляет к памяти менее жесткие требования. Это означает, что при прочих равных условиях объем работы по сборке мусора уменьшается, а рабочее пространство для кода приложения увеличивается. Хотя этот результат и не отражен в таблице, он положительно влияет на общую производительность приложения. Разумеется, у решения, основанного на пользовательском формате данных, имеются и недостатки по сравнению с вариантами решений, в которых используются объекты ADO.NET DataSet. Самое главное — это то, что при необходимости обновления данных на сервере в нашем коде требуется организовать учет всех изменений данных. Это означает, что мы должны ввести, по крайней мере, один дополнительный столбец булевских значений, указывающих на то, в каких строках были сделаны изменения. Это не составляет особого труда в случае простых табличных данных, но значительно усложняется, если данные разбросаны по нескольким таблицам и связаны между собой целой системой различных отношений. Кроме того, ADO.NET предлагает объекты DataView, обеспечивающие сортировку и фильтрацию данных, чего мы лишены, если останавливаемся на варианте пользовательской реализации модели данных. Расширение возможностей связано с дополнительными накладными расходами, и поэтому вы должны тщательно взвешивать все за и против, выбирая между функциональностью Al)O.NET и потенциально более высокой эффективностью пользовательской реализации. В случае приложений для устройств повышение эффективности часто окупает дополнительные затраты труда на разработку пользовательской модели данных на стадии проектирования. Таблица 14.2. Сравнение производительности варианта приложения с пользовательским форматом данных, выполняющегося на физическом устройстве Pocket PC, с предыдущими результатами
Приведенный в листинге 14.4 код необходимо включить в форму в проекте Pocket PC. Для создания и выполнения приложения потребуется выполнить следующие действия: 1. Запустите Visual Studio .NET (2003 или более позднюю версию) и выберите в качестве типа приложения C# Smart Device Application. 2. Выберите в качестве целевой платформы Pocket PC. (Для вас будет автоматически создан проект, и на экране появится окно конструктора форм Pocket PC.) 3. Добавьте в форму элемент управления Button. Присвойте ему имя buttonRunTest. 4. Дважды щелкните на элементе управления Button в окне конструктора форм. В автоматически сгенерированной и подключенной функции обработчика событий введите код функции buttonRunTest_Click() из листинга 14.4. 5. Введите весь оставшийся код в тот же класс. 6. Установите для свойства MinimizeBox формы значение false. Благодаря этому во время выполнения в верхней правой части формы появится кнопка OK, с помощью которой вы легко сможете закрыть форму и выйти из приложения. Эта возможность оказывается очень полезной при многократном тестировании приложения. 7. Запустите приложение, нажав клавишу <F5>. Щелкните на кнопке для запуска теста. Результаты тестирования должны отобразиться в окне сообщений. Листинг 14.4. Результаты тестирования производительности при использовании пользовательского формата данных вместо объектов DataSet//Определение размерных характеристик теста const int DUMMY_ROWS_OF_DATA = 100; const int NUMBER_TEST_ITERATIONS = 500; const string TABLE_NAME_PASSENGERINFO = "CustomerTravelInfo"; const string TEST_CREDIT_CARD = "IvoCard-987-654-321-000"; string [] m_data_creditCards; string [] m_data_names; System.DateTime [] m_data_travelDates; //------------------------------------------------------------- //Создает массив данных (вместо использования объектов DataSet) //------------------------------------------------------------- private void createDataSet() { //============================================= //1. Создать пространство для размещения данных //============================================= m_data_creditCards = new string[DUMMY_ROWS_OF_DATA + 1]; m_data_names = new string[DUMMY_ROWS_OF_DATA + 1]; m_data_travelDates = new System.DateTime[DUMMY_ROWS_OF_DATA + 1]; //---------------------- //Добавить строки данных //---------------------- System.Text.StringBuilder buildTestString; buildTestString = new System.Text.StringBuilder(); for (int addItemsCount = 0; addItemsCount < DUMMY_ROWS_OF_DATA; addItemsCount++) { //Выбрать день отъезда пассажира m_data_travelDates[addItemsCount] = System.DateTime.Today.AddDays(addItemsCount); //--------------------- //Выбрать имя пассажира //--------------------- //Очистить строку buildTestString.Length = 0; buildTestString.Append("TestPersonName"); buildTestString.Append(addItemsCount); m_data_names[addItemsCount] = buildTestString.ToString(); //------------------------------------------------------- //Связать с пассажиром текстовый номер кредитной карточки //------------------------------------------------------- //Строка значения третьего столбца набора данных buildTestString.Length = 0; buildTestString.Append("IvoCard-000-000-0000-"); buildTestString.Append(addItemsCount); m_data_creditCards[addItemsCount] = buildTestString.ToString(); } //Добавить элемент, поиск которого мы хотим выполнить в нашем тесте... //Выбрать день для значения в первом столбце данных m_data_travelDates[DUMMY_ROWS_OF_DATA] = System.DateTime.Today; //Строка для второго столбца данных m_data_names[DUMMY_ROWS_OF_DATA] = "Ms. TestPerson"; //Строка с идентификатором кредитной карточки m_data_creditCards[DUMMY_ROWS_OF_DATA] = ТЕST_CRE DIT_CARD; } //Конец функции //----------------- //Выполнить тест... //----------------- void changeDayOfTravel_test() { //Отобразить курсор ожидания System.Windows.Forms.Cursor.Current = System.Windows.Forms.Cursors.WaitCursor; //Начать с известной даты... System.DateTime newDate; newDate = System.DateTime.Today; changeDayOfTravel_CustomArrays(ТЕST_CREDIT_CARD, newDate); //ТОЛЬКО В ЦЕЛЯХ ТЕСТИРОВАНИЯ!!! //HE СЛЕДУЕТ использовать вызовы сборщика мусора в готовом программном //коде. Это ЗАМЕДЛЯЕТ работу приложения. System.GC.Collect(); const int testNumber = 0; //Запустить таймер теста PerformanceSampling.StartSample(testNumber, "Custom Array implementation"); //Запустить тест! for(int testCount = 0; testCount < NUMBER_TEST_ITERATIONS; testCount++) { //Передвинуть дату вперед на один день newDate = newDate.AddDays(1); int numberRecordsChanged = 0; //Просмотреть все имена, используя СТРОКИ numberRecordsChanged = changeDayOfTravel_CustomArrays(TEST_CREDIT_CARD, newDate); //Убедиться в нормальном выполнении теста... if (numberRecordsChanged != 1) { System.Windows.Forms.MessageBox.Show("No matching records found. Test aborted!"); return; } } //Получить время выполнения теста PerformanceSampling.StopSample(testNumber); //Обычный курсор System.Windows.Forms.Cursor.Current = System.Windows.Forms.Cursors.Default; //Отобразить результаты теста string runInfo = NUMBER_TEST_ITERATIONS.ToString() + "x" + DUMMY_ROWS_OF_DATA.ToString() + ": "; System.Windows.Forms.MessageBox.Show(runInfo + PerformanceSampling.GetSampleDurationText(testNumber)); } private int changeDayOfTravel_CustomArrays(string creditCardNumber, System.DateTime newTravelDate) { int numberRecordsChanged = 0; //Просмотреть каждый элемент массива for (int index = 0; index <= DUMMY_ROWS_OF_DATA; index++) { string currentCreditCard; currentCreditCard = m_data_creditCards[index]; //Обновить запись при наличии совпадения if (creditCardNumber == currentCreditCard) { //Изменить дату поездки System.DateTime currentTravelDate = m_data_travelDates[index]; //Увеличить значение счетчика обновлений только при несовпадении данных if (currentTravelDate != newTravelDate) { m_data_travelDates[index] = newTravelDate; numberRecordsChanged++; } } } //Возвратить количество обновленных записей return numberRecordsChanged; } private void buttonRunTest_Click(object sender, System.EventArgs e) { createDataSet(); changeDayOfTravel_test(); }Пример использования базы данных на устройстве и управления пользовательскими данными Чтобы проиллюстрировать методы представления и управления пользовательскими данными, считанными из базы данных в память, полезно вернуться к примеру из предыдущей главы. В настоящем примере мы вновь рассмотрим словарную игру, для которой разрабатывали пользовательский интерфейс в главе 13. Ранее нас интересовали вопросы проектирования пользовательского интерфейса для этого мобильного приложения, а теперь мы будем исследовать хранение и представление в памяти самих слов, образующих словарь. Поскольку словарь, который мы хотели бы использовать для данного мобильного приложения, может оказаться очень большим, то, исходя из соображений быстродействия, эффективности и гибкости приложения, для хранения данных желательно использовать базу данных. По своей природе наши данные предназначены в основном только для чтения; время от времени пользователь может добавлять в словарь новые слова, но динамическое обновление существующих данных не является главным требованием. Кроме того, данные имеют простую структуру и их легко можно представить в виде одной таблицы базы данных. В силу всех вышеуказанных причин — потенциально большое количество записей, низкая частота обновления и простота структуры данных — возможности подхода, основанного на использовании объектов ADO.NET DataSet, намного превышают уровень наших потребностей. Мы вполне можем обойтись оптимизированным решением, используя низкоуровневые возможности класса SQL СЕ DataReader (System.Data. SqlServerCe.SqlCeDataReader) для выполнения запросов к локальной базе данных SQL СЕ нашего устройства. В результате запросов наше приложение будет получать однонаправленный курсор, указывающий на данные, которые отвечают критерию запроса. Далее эти данные можно загрузить в память и сохранить в пользовательском формате, специально подобранном таким образом, чтобы обеспечить наиболее эффективную работу со словарем. В интересах простоты и быстродействия соответствующие объекты будут размещаться в массивах. Тем самым будет достигнута существенная экономия времени и памяти по сравнению с общим подходом, основанным на использовании объектов DataSet, поскольку мы размещаем в памяти лишь те объекты, которые действительно будут использоваться в нашем приложении. Следует обратить ваше внимание на два момента, которые используются в нашем примере с целью его упрощения, но вряд ли встретятся вам в реальных приложениях для мобильных устройств: 1. Содержимое базы данных формируется тем же приложением, которое загружает данные из базы данных. Если бы во время проектирования нам были известны все данные, которые потребуются приложению во время выполнения, то и потребность во внешней базе данных была бы небольшой; приложению достаточно заполнить структуры данных в памяти непосредственно в коде и отказаться от накладных расходов, с которыми сопряжена поддержка любой базы данных. В реальной версии данного приложения мы создали бы и заполнили данными базу данных, используя один из трех механизмов: а) загрузка в устройство файла уже наполненной базы данных, которую мы предварительно создали; б) синхронизация базы данных SQL СЕ с серверным вариантом SQL-сервера; и в) выполнение и завершение единственного приложения без сохранения данных созданной и наполненной им базы данных. 2. В память загружаются сразу все данные. Как выше уже отмечалось, словарь для нашего приложения может иметь очень большие размеры. Если бы наша база включала 20000 слов, то, вероятно, мы не захотели бы считывать в память все эти слова одновременно. Пользователь от этого ничего не выигрывает, поскольку в любой момент времени он одновременно работает только с небольшим набором из нескольких слов. Мы бы просто выбрали какой-то разумный предел, ограничивающий количество слов, которое наше приложение загружает в каждый момент времени; далее приложение может периодически обновлять встроенный в память кэш новыми словами. Например, мы хотим удерживать в словаре, хранящемся в памяти, не более 500 слов из полной базы данных словаря, насчитывающей 20 000 слов, из которых в любой момент времени только от 1 до 40 слов должны быть загружены в память. Было бы легко обновить код, осуществляющий считывание слов таким образом, чтобы для каждого слова, которое встречалось, вероятность загрузки составляла 1/40. Возможны и другие стратегии минимизации количества слов, хранимых в памяти, такие как группирование слов в родственные наборы, загружаемые целиком (например, простые слова, слова повышенной трудности, особо трудные слова). В любом случае мы хотим, чтобы наше мобильное приложение располагало системой управления памятью, которая гарантировала бы, что в любой момент времени в память загружается лишь ограниченное количество слов, так что независимо от того, какой размер имеет база данных, приложение нормально функционирует вполне предсказуемым образом. Приведенный в листинге 14.5 код должен быть включен в форму в проекте Pocket PC. Код в листингах 14.6, 14.7 и 14.8 представляет отдельные, полностью определенные классы. Для создания и выполнения приложения необходимо выполнить следующие действия: 1. Запустите Visual Studio .NET (2003 или более позднюю версию) и выберите в качестве типа приложения C# Smart Device Application. 2. Выберите в качестве целевой платформы Pocket PC. (Для вас будет автоматически создан проект, и на экране появится окно конструктора форм Pocket PC.) 3. Добавьте в проект ссылку на класс SqlServerCE. Это можно сделать, щелкнув правой кнопкой мыши на узле References в элементе управления TreeView в окне Solution Explorer, а затем выбрав элемент System.Data. SqlServerCe. Эта ссылка позволяет нашему приложению использовать классы из сборки System.Data.SqlServerCe, что открывает нам доступ к программной модели SQLCE 4. Добавьте в форму следующие элементы управления: а. Кнопку (Button), переименовав ее в buttonCreateDataBase. б. Кнопку (Button), переименовав ее в buttonLoadGameData в. Текстовое окно (TextBox), оставив автоматически присвоенное ему имя textBox1. 5. Установите для свойства MultiLine элемента управления TextBox значение true. 6. Установите для свойства ScrollBar элемента управления TextBox значение vertical. 7. Для каждой из вышеупомянутых кнопок выполните следующие действия. Дважды щелкните на кнопке в окне конструктора форм. В автоматически сгенерированной и подключенной функции обработчика событий введите код функции button<ИмяКнопки>_Click() из листинга 14.5. 8. Установите для свойства MinimizeBox формы значение false. Благодаря этому во время выполнения в верхней правой части формы появится кнопка OK, с помощью которой вы легко сможете закрыть форму и выйти из приложения. Эта возможность оказывается очень полезной при многократном тестировании приложения. 9. Добавьте в проект класс DatabaseAccess, удалите из него весь добавленный по умолчанию код в окне редактора класса, и введите вместо него код из листинга 14.6. 10. Добавьте в проект класс GameData, удалите из него весь добавленный по умолчанию код в окне редактора класса, и введите вместо него код из листинга 14.7. 11. Добавьте в проект класс VocabularyWord, удалите из него весь добавленный по умолчанию код в окне редактора класса, и введите вместо него код из листинга 14.8. 12. Запустите приложение, нажав клавишу <F5>. Пользовательский интерфейс приложения должен выглядеть примерно так, как показано на рис. 14.4. Щелкните на кнопке buttonCreateDatabase для создания и наполнения данными базы данных SQL СЕ. Щелкните на кнопке buttonGameData с целью загрузки содержимого базы данных в память для последующего использования; в результате этого в текстовом окне должны отобразиться слова из словаря.  Рис. 14.4. Пример управления данными не с помощью объектов DataSet Листинг 14.5. Пример пользовательского управления данными — код, помещаемый в форму Form1.cs //Создает базу данных private void buttonCreateDatabase_Click(object sender, System.EventArgs e) { DatabaseAccess.CreateAndFillDatabase(); } //Загружает данные из базы данных и отображает их private void buttonLoadGameData_Click(object sender, System.EventArgs e) { //Очистить текстовое окно textBox1.Text = ""; //Загрузить данные для слов GameData.InitializeGameVocabulary(); //Обойти все слова и добавить их в текстовый список System.Text.StringBuilder thisStringBuilder; thisStringBuilder = new System.Text.StringBuilder(); foreach (VocabularyWord thisWord in GameData.AllWords) { thisStringBuilder.Append(thisWord.EnglishWord); thisStringBuilder.Append(" = "); thisStringBuilder.Append(thisWord.GermanWordWithArticleIfExists); thisStringBuilder.Append("\r\n"); //Новая строка } //Отобразить список слов в текстовом окне textBox1.Text = thisStringBuilder.ToString(); }Листинг 14.6. Пример кода управления данными для DatabaseAccess.cs //------------------------------------------------------------ //Код доступа к базе данных // //Этот класс управляет доступом к базе данных наших приложений //------------------------------------------------------------ using System; internal class DatabaseAccess { const string DATABASE_NAME = "LearnGerman.sdf"; const string CONNECT_STRING = "Data Source = " + DATABASE_NAME + "; Password = ''"; const string TRANSLATIONTABLE_NAME = "TranslationDictionary"; const string TRANSLATIONTABLE_ENGLISH_COLUMN = "EnglishWord"; const string TRANSLATIONTABLE_GERMAN_COLUMN = "GermanWord"; const string TRANSLATIONTABLE_GERMANGENDER_COLUMN = "GermanGender"; const string TRANSLATIONTABLE_ WORDFUNCTION_COLUMN = "WordFunction"; internal const int DS_WORDS_COLUMNINDEX_ENGLISHWORD = 0; internal const int DS_WORDS_COLUMNINDEX_GERMANWORD = 1; internal const int DS_WORDS_COLUMNINDEX_GERMANGENDER = 2; internal const int DS_WORDS_COLUMNINDEX_WORDFUNCTION = 3; static public System.Data.IDataReader GetListOfWords() { System.Data.SqlServerCe.SqlCeConnection conn = null; conn = new System.Data.SqlServerCe.SqlCeConnection(CONNECT_STRING); conn.Open(); System.Data.SqlServerCe.SqlCeCommand cmd = conn.CreateCommand(); cmd.ConmandText = "select " + TRANSLATIONTABLE_ENGLISH_COLUMN + ", " + TRANSLATIONTABLE_GERMAN_COLUMN + ", " + TRANSLATIONTABLE_GERMANGENDER_COLUMN + ", " + TRANSLATIONTABLE_WORDFUNCTION_COLUMN + " " + "from " + TRANSLATIONTABLE_NAME; //Выполнить команду базы данных System.Data.SqlServerCe.SqlCeDataReader myReader = cmd.ExecuteReader(System.Data.CommandBehavior.SingleResult); return myReader; } //------------------------------------------ //Создает базу данных в случае необходимости //------------------------------------------ static public void CreateDatabaseIfNonExistant() { if (System.IO.File.Exists(DATABASE_NAME) == false) { CreateAndFillDatabase(); } } //--------------------------------------- //Создает и наполняет данными базу данных //--------------------------------------- static public void CreateAndFillDatabase() { //Удалить базу данных, если она уже существует if (System.IO.File.Exists(DATABASE_NAME)) { System.IO.File.Delete(DATABASE_NAME); } //Создать новую базу данных System.Data.SqlServerCe.SqlCeEngine sqlCeEngine; sqlCeEngine = new System.Data.SqlServerCe.SqlCeEngine(CONNECT_STRING); sqlCeEngine.CreateDatabase(); //------------------------------------- //Попытаться подключиться к базе данных //и наполнить ее данными //------------------------------------- System.Data.SqlServerCe.SqlCeConnection conn = null; try { conn = new System.Data.SqlServerCe.SqlCeConnection(CONNECT_STRING); conn.Open(); System.Data.SqlServerCe.SqlCeCommand cmd = conn.CreateCommand(); //Создает таблицу перевода //Поля: // 1. Слова на английском языке (English) // 2. Слова на немецком языке (German) // 3. Грамматический род (Gender) // 4. Тип слова cmd.CommandText = "CREATE TABLE " + TRANSLATIONTABLE_NAME + " (" + TRANSLATIONTABLE_ENGLISH_COLUMN + " ntext" + ", " + TRANSLATIONTABLE_GERMAN_COLUMN + " ntext" + ", " + TRANSLATIONTABLE_GERMANGENDER_COLUMN + " int" + ", " + TRANSLATIONTABLE_WORDFUNCTION_COLUMN + " int" + ")"; cmd.ExecuteNonQuery(); //Наполнить базу данных словами FillDictionary(cmd); } catch (System.Exception eTableCreate) { System.Windows.Forms.MessageBox.Show("Error occurred adding table :" + eTableCreate.ToString()); } finally { //Всегда закрывать базу данных по окончании работы conn.Close(); } //Информировать пользователя о создании базы данных System.Windows.Forms.MessageBox.Show("Created langauge database!"); } static private void FillDictionary(System.Data.SqlServerCe.SqlCeCommand cmd) { //Глаголы InsertEnglishGermanWordPair(cmd, "to pay", "zahlen", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Verb); InsertEnglishGermanWordPair(cmd, "to catch", "fangen", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Verb); //Добавить другие слова... //Местоимения InsertEnglishGermanWordPair(cmd, "What", "was", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Pronoun); //Добавить другие слова... //Наречия InsertEnglishGermanWordPair(cmd, "where", "wo", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Adverb); InsertEnglishGermanWordPair(cmd, "never", "nie", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Adverb); //Добавить другие слова... //Предлоги InsertEnglishGermanWordPair(cmd, "at the", "am", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Preposition); //Имена прилагательные InsertEnglishGermanWordPair(cmd, "invited", "eingeladen", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Verb); InsertEnglishGermanWordPair(cmd, "yellow", "gelbe", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Adjective); InsertEnglishGermanWordPair(cmd, "one", "eins", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Adjective); InsertEnglishGermanWordPair(cmd, "two", "zwei", VocabularyWord.WordGender.notApplicable, VocabularyWord.WordFunction.Adjective); //Имена существительные мужского рода InsertEnglishGermanWordPair(cmd, "Man", "Mann", VocabularyWord.WordGender.Masculine, VocabularyWord.WordFunction.Noun); InsertEnglishGermanWordPair(cmd, "Marketplace", "Marktplatz", VocabularyWord.WordGender.Masculine, VocabularyWord.WordFunction.Noun); InsertEnglishGermanWordPair(cmd, "Spoon", "Löffel", VocabularyWord.WordGender.Masculine, VocabularyWord.WordFunction.Noun); //Имена существительные женского рода InsertEnglishGermanWordPair(cmd, "Woman", "Frau", VocabularyWord.WordGender.Feminine, VocabularyWord.WordFunction.Noun); InsertEnglishGermanWordPair(cmd, "Clock", "Uhr", VocabularyWord.WordGender.Feminine, VocabularyWord.WordFunction.Noun); InsertEnglishGermanWordPair(cmd, "Cat", "Katze", VocabularyWord.WordGender.Feminine, VocabularyWord.WordFunction.Noun); //Имена существительные среднего рода InsertEnglishGermanWordPair(cmd, "Car", "Auto", VocabularyWord.WordGender.Neuter, VocabularyWord.WordFunction.Noun); InsertEnglishGermanWordPair(cmd, "Book", "Buch", VocabularyWord.WordGender.Neuter, VocabularyWord.WordFunction.Noun); } //---------------------------- //Помещает слово в базу данных //---------------------------- static private void InsertEnglishGermanWordPair( System.Data.SqlServerCe.SqlCeCommand cmd, string englishWord, string germanWord, VocabularyWord.WordGender germanWordGender, VocabularyWord.WordFunction wordFunction) { cmd.CommandText = "INSERT INTO " + TRANSLATIONTABLE_NAME + "(" + TRANSLATIONTABLE ENGLISH_COLUMN + ", " + TRANSLATIONTABLE_GERMAN_COLUMN + ", " + TRANSLATIONTABLE_GERMANGENDER_COLUMN + ", " + TRANSLATIONTABLE_WORDFUNCTION_COLUMN + ") VALUES ('" + englishWord + "', '" + germanWord + "', '" + System.Convert.ToString(((int) germanWordGender))+ "', '" + System.Convert.ToString(((int) wordFunction)) + "' )"; cmd.ExecuteNonQuery(); } } //Конец классаЛистинг 14.7. Пример кода управления данными для GameData.cs //----------------------------------------------------------------- //Код управления данными в памяти // //Этот код предназначен для управления представлением кода в памяти //----------------------------------------------------------------- using System; internal class GameData { //Массив списков для сохранения загружаемых данных private static System.Collections.ArrayList m_vocabularyWords All; private static System.Collections.ArrayList m_vocabularyWords_Nouns; private static System.Collections.ArrayList m_vocabularyWords_Verbs; private static System.Collections.ArrayList m_vocabularyWords_Adjectives; private static System.Collections.ArrayList m_vocabularyWords_Adverbs; private static System.Collections.ArrayList m_vocabularyWords_Prepositions; public static bool isGameDataInitialized { //Инициализация данных игры, если слова загружены get { return (m_vocabularyWords_All != null); } } //Возвращает коллекцию всех имеющихся слов public static System.Collections.ArrayList AllWords { get { //Загрузить данные, если они не были инициализированы if (m_vocabularyWords_All == null) { InitializeGameVocabulary(); } return m_vocabularyWords_All; } } //Возвращает коллекцию всех имеющихся имен существительных public static System.Collections.ArrayList Nouns { get { //Загрузить данные, если они не были инициализированы if (m_vocabularyWords_Nouns == null) { InitializeGameVocabulary(); } return m_vocabularyWords_Nouns; } } //========================================================== //Загружает данные из нашей базы данных //========================================================== static public void InitializeGameVocabulary() { //Создать новый массив списков для хранения наших слов m_vocabularyWords_All = new System.Collections.ArrayList(); m_vocabularyWords_Nouns = new System.Collections.ArrayList(); m_vocabularyWords Verbs = new System.Collections.ArrayList(); m_vocabularyWords_Adjectives = new System.Collections.ArrayList(); m_vocabularyWords_Adverbs = new System.Collections.ArrayList(); m_vocabularyWords_Prepositions = new System.Collections.ArrayList(); System.Data.IDataReader dataReader; dataReader = DatabaseAccess.GetListOfWords(); VocabularyWord newWord; //Обойти все записи while (dataReader.Read()) { //Поместить данные для только что считанного слова в класс newWord = new VocabularyWord( dataReader.GetString(DatabaseAccess.DS_WORDS_COLUMNINDEX_ENGLISHWORD), dataReader.GetString(DatabaseAccess.DS_WORDS COLUMNINDEX_GERMANWORD), (VocabularyWord.WordGender)dataReader.GetInt32(DatabaseAccess.DS_WORDS_COLUMNINDEX_GERMANGENDER), (VocabularyWord.WordFunction)dataReader.GetInt32(DatabaseAccess.DS_WORDS_COLUMNINDEX_WORDFUNCTION)); //Добавить новое слово в массив списков m_vocabularyWords_All.Add(newWord); //Слова могут принадлежать нескольким группам, поэтому необходимо //выполнить проверку с использованием операции логического И //для проверки того, что слово относится к данной категории if ((newWord.getWordFunction & VocabularyWord.WordFunction.Noun) ! = 0) { m_vocabularyWords_Nouns.Add(newWord); } if ((newWord.getWordFunction & VocabularyWord.WordFunction.Verb) != 0) { m_vocabularyWords_Verbs.Add(newWord); } if ((newWord.getWordFunction & VocabularyWord.WordFunction.Adjective) != 0) { m_vocabularyWords Adjectives.Add(newWord); } if ((newWord.getWordFunction & VocabularyWord.WordFunction.Adverb) != 0) { m_vocabularyWords Adverbs.Add(newWord); } if ((newWord.getWordFunction & VocabularyWord.WordFunction.Preposition) != 0) { m_vocabularyWords_Prepositions.Add(newWord); } } //Закрыть объект DataReader dataReader.Close(); } } //Конец классаЛистинг 14.8. Пример кода управления данными для VocabularyWord.cs using System; //------------------------------ //Хранит данные слова из словаря //------------------------------ internal class VocabularyWord { [System.FlagsAttribute] //Значения можно объединять с помощью операции //логического ИЛИ public enum WordFunction { Noun = 1, Verb = 2, Pronoun = 4, Adverb = 8, Adjective = 16, Preposition = 32, Phrase = 64 } public enum WordGender { notApplicable = 0, Masculine = 1, Feminine = 2, Neuter = 3, } private string m_englishWord; private string m_germanWord; private VocabularyWord.WordGender m_germanGender; private VocabularyWord.WordFunction m_wordFunction; public string EnglishWord{ get { return m_englishWord; } } public string GermanWord{ get { return m_germanWord; } } public WordFunction getWordFunction { get { return m_wordFunction; } } public WordGender GermanGender{ get { return m_germanGender; } } //----------------------------------------------------------------- //Возвращает слово на немецком языке, которому предшествует артикль //{например, 'der', 'die', 'das'), если он существует //----------------------------------------------------------------- public string GermanWordWithArticleIfExists { get { if (m_germanGender == WordGender.notApplicable) { return this.GermanWord; } return this.GenderArticle +" " + this.GermanWord; } } //Конец свойства public string GenderArticle { get { switch (m_germanGender) { case WordGender.Masculine: return "der"; case WordGender.Feminine: return "die"; case WordGender.Neuter: return "das"; } return ""; } } public VocabularyWord(string enlgishWord, string germanWord, WordGender germanGender, WordFunction wordFunction) { m_englishWord = enlgishWord; m_germanWord = germanWord; m_germanGender = germanGender; m_wordFunction = wordFunction; } } //Конец класса Различные способы хранения долговременных данныхСуществует много различных способов хранения данных мобильных приложений. Данные можно сохранять в двоичных файлах, текстовых файлах и базах данных. (Базу данных можно считать частным случаем двоичного файла.) Хранение данных может быть реализовано вне устройства или на устройстве. Долговременные данные могут синхронизироваться между устройствами и серверами. Ниже описаны преимущества и недостатки наиболее распространенных вариантов хранения данных, а также приведены рекомендации относительно того, как подходить к принятию решений относительно организации долговременного хранения данных при проектировании приложений для мобильных устройств. Хранение данных в виде XML-файлов на устройстве■ Преимущества. Текстовые файлы можно отлично использовать для хранения средних объемов долговременных данных. XML-файлы обеспечивают достижение разумного баланса между пользовательскими и структурными форматами и являются шагом вперед по сравнению с обычными текстовыми файлами. XML-файлы могут легко передаваться между настольными компьютерами, серверами и устройствами и без особого труда интерпретироваться различными приложениями. Учитывая простоту и гибкость XML файлов, найти для них конкурента очень трудно. ■ Недостатки. Текстовые файлы характеризуются увеличенными размерами, но размеры XML-файлов еще больше. Если ваше мобильное приложение работает с множеством данных, эффективное хранение которых необходимо организовать, то XML-файлы для этого не годятся. Кроме того, XML-файлы представляют собой форматированный текст, их содержимое можно легко прочитать и они не обеспечивают защиту данных; по этой причине следует избегать их использования для хранения критически важной информации, если только вы не располагаете надежным механизмом шифрования файлов.Примечание. Дополнительные рекомендации по использованию XML для эффективного хранения файлов содержатся в главе 10. Хранение данных в базах данных SQL СЕ на устройствах■ Преимущества. Наличие процессора базы данных на устройстве открывает очень широкие возможности. Встроенные базы данных обеспечивают приложению возможность локального хранения, управления и запроса больших объемов информации. Базы данных SQL СЕ могут защищаться паролями и поэтому обеспечивают безопасность хранения критически важной информации. Между базами данных SQL СЕ и серверными базами данных SQL можно устанавливать партнерские отношения, что обеспечивает широкие возможности их синхронизации между собой. Для приложений, которым приходится иметь дело с множеством данных, нуждающихся в локальном управлении, этот выбор, вероятно, является наилучшим. ■ Недостатки. Самый большой недостаток использования встроенных баз данных состоит в необходимости проверки того, установлен ли процессор базы данных на вашем целевом устройстве. Сама база данных SQL СЕ занимает значительный объем памяти устройства (1-3 Мбайт) и обычно должна устанавливаться на нем, так как нередко она не является частью образа устройства в ПЗУ. Из-за требований к объему памяти не все классы устройств поддерживают размещение процессора базы данных SQL СЕ. Например, в настоящее время размещение SQL СЕ поддерживается Pocket PC, но не поддерживается смартфонами. Кроме занимаемого объема памяти, играют роль и требования синхронизации. Перемещение данных, хранящихся в локальной базе данных устройства, на другой компьютер потребует от вас написания кода соответствующей логики; для перемещения данных между устройствами вам может понадобиться упаковка данных в виде ADO.NET DataSet или привлечение пользовательского формата данных. Хранение данных в базах данных SQL вне устройства (на сервере)■ Преимущества. Использование для хранения данных и обращения к ним базы данных, расположенной на сервере, является эффективным способом доступа к почти неограниченным объемам данных. ■ Недостатки. Для получения данных с сервера или обновления данных на сервере необходимо установить соединение. Если ваше мобильное приложение использует внешнюю базу данных в качестве основного источника данных, планируйте написание пользовательской логики для временного локального сохранения данных в случае разрыва соединения; нет ничего хуже, чем потерять данные в результате сбоя связи при попытке выполнить их обновление на сервере. Мобильным устройствам все время приходится сталкиваться с сетевыми сбоями, и ваше мобильное приложение должно уметь справляться с такими трудностями, возникающими при работе в реальных условиях. Другим потенциальным недостатком обращения к данным на сервере является необходимость считаться с правилами доступа, принятыми в частных сетях, и с брандмауэрами. Большинство серверных баз данных, содержащих ценную информацию, находятся в защищенных средах позади брандмауэров. Брандмауэр может не дать вашему мобильному приложению соединиться с базой данных сервера, если устройство находится за пределами частной сети. Если требуется доступ к данным на защищенном сервере, то вы должны решить вопрос о том, как сделать такой доступ возможным. Доступ к данным, хранящимся вне устройств, посредством Web-служб■ Преимущества. Web-службы все чаще используются в качестве оболочек доступа к коммерческим источникам данных. Доступ к информации, хранящейся в базах данных, может обеспечиваться через Web-службы без предоставления непосредственного доступа к самим базам данных. Обычно Web-службы работают посредством сетевых протоколов HTTP или HTTPS; как правило, брандмауэры ведут себя дружественно по отношению к этим протоколам. Если сеть уже поддерживает выходной сервер, то создать Web-службу, размещенную на этом сервере, как правило, относительно просто. Новейшие процессоры баз данных усиленно поддерживают возврат данных в виде XML, позволяя обходиться без промежуточного Web-сервера. Эти базы данных фактически предлагают собственные Web-службы. XML-данные, возвращенные непосредственно базой данных, не обязательно будут иметь формат данных ADO.NET XML DataSet, но любые возвращенные XML-данные можно синтаксически проанализировать и обработать на устройстве, если такой способ работы с ними является наилучшим. В обоих случаях обмен данными с мобильными устройствами может осуществляться посредством потоков с использованием формата данных ADO.NET DataSet в виде XML или любого другого формата XML-данных. Выбирая между вариантами непосредственной связи с базой данных или изоляцией базы данных при помощи промежуточного Web-сервера, следует исходить из соображений безопасности, производительности, а также простоты разработки и развертывания приложения. ■ Недостатки. Как и в случае использования внешних баз данных, невозможно гарантировать, что сетевой доступ к Web-службам будет обеспечен в любой момент времени. Чтобы ваше приложение было полезным и надежным, для него всегда необходимо предусматривать стратегию на случай сбоя связи, позволяющую работать с локальными кэшированными данными, если сеть недоступна. Еще одним недостатком является недостаточная эффективность связи. Поскольку в качестве основного коммуникационного механизма Web-службы используют XML, то предоставляемая ими информация занимает больший объем по сравнению с такими, например, специализированными форматами, как те, которые используются для синхронизации баз данных. Если имеется значительный объем данных, которые необходимо загрузить или выгрузить, то, вероятно, целесообразно рассмотреть возможность использования механизма непосредственного доступа к базе данных, основанного на наиболее эффективном из имеющихся протоколов. SQL СЕС небольшими объемами данных, которые обладают простой структурой, еще можно справиться с помощью файлов XML, однако при превышении некоторого объема и сложности данных ваше приложение значительно выиграет, а его разработка намного упростится, если вы используете формальную базу данных. Хотя и не существует абсолютных правил относительно того, когда именно вместо XML-файлов следует воспользоваться базой данных, чем больше объем данных, тем целесообразнее становится переход к базе данных. Как правило, если ожидается, что количество строк данных, с которыми придется работать вашему мобильному приложению, больше ста, или информация должна храниться в нескольких таблицах, то, вероятно, имеет смысл использовать установленную на устройстве базу данных, например SQL СЕ. По SQL СЕ существует хорошая документация в сети. Читателям, которые хотели бы получить более подробную информацию относительно SQL СЕ, можно порекомендовать провести поиск по ключевым словам "SQL Server СЕ" в библиотеке MSDN в сети (или в справочной документации по Visual Studio). Вместо того чтобы пытаться подробно пересказать уже имеющуюся в указанных источниках информацию, в этом разделе будет приведен краткий обзор SQL СЕ и описаны важные решения, которые должны быть приняты в процессе разработки кода мобильного приложения, предназначенного для работы с такими базами данных, установленными на устройстве, как SQL СЕ. Простой пример, демонстрирующий использование базы данных SQL СЕ, приводился ранее в данной главе в листингах 14.5, 14.6, 14.7 и 14.8. Что такое SQL СЕ?SQL СЕ, формальным названием которой является SQL Server СЕ, — это процессор базы данных для мобильных и встроенных устройств. Эта база данных располагает относительно богатыми функциональными возможностями в отношении хранения и запроса структурированных данных и их синхронизации с серверами. На одном устройстве могут быть созданы одновременно несколько баз данных SQL СЕ. Каждая из баз данных на устройстве представляется единственным двоичным файлом; эти файлы можно вручную копировать с одного устройства на другое и автоматически синхронизировать с базой данных на сервере. Содержимое базы данных SQL СЕ может быть зашифровано с помощью пароля, что обеспечит разумный уровень безопасности данных в том случае, если устройство украдено или утеряно или его содержимое тайком скопировано. SQL СЕ представляет собой подмножество функциональных возможностей версий базы данных SQL Server, ориентированных на настольные компьютеры и серверы. SQL СЕ поддерживает хранение реляционных данных в таблицах, а также значительную часть типов данных SQL и синтаксиса запросов для добавления, извлечения и изменения данных. Следует подчеркнуть, что в настоящее время SQL СЕ не поддерживает сохраненные процедуры или именованные параметры в запросах. Другие базы данных для мобильных устройств и модели лицензирования баз данныхНезависимый и синхронизированный режимы работы базы данных SQL СЕ. SQL СЕ может использоваться в одном из трех режимов: 1. Автономный режим. В этой модели использования база данных SQL СЕ служит в качестве автономной базы данных на устройстве. Аналогом этого на настольном компьютере является использование локальных процессоров баз данных SQL Server или Access для управления локальной базой данных. Одна из основных трудностей при использовании автономной базы данных SQL СЕ заключается в выборе правильной стратегии наполнения базы данных. Ваше приложение может либо динамически заполнять базу данных внешними данными, получаемыми устройством во время выполнения, либо использовать готовый файл базы данных, копируемый на устройство. Возможно и сочетание указанных моделей; данные могут динамически добавляться в существующий файл базы данных, который был загружен на устройство. Какая стратегия заполнения базы данных является наилучшей, зависит от природы вашего приложения. Если вы используете предварительно заполненную базу данных, то самый простой способ доставки этих данных заключается в создании эталонной копии базы данных на Pocket PC как части вашего процесса разработки и последующего копирования этой базы данных с устройства на машину, которая используется для осуществления разработки. Такая предварительно заполненная база данных может далее быть скопирована на все целевые устройства в процессе развертывания приложения. 2. Синхронизация с SQL-сервером через Web-cepвep (IIS). Этот механизм известен под названием удаленного доступа к данным (remote data access — RDA). Он представляет собой простой метод синхронизации, в соответствии с которым SQL- сервер, содержащий эталонную копию данных, никак специально не связан с базами данных SQL СЕ, которые с ним синхронизируются. Базы данных SQL СЕ получают доступ к серверным данным точно так же, как любое другое клиентское приложение базы данных, за исключением того, что доступ осуществляется через интерфейс Web-cepвepa. Поскольку серверная база данных не должна отслеживать, какие данные хранятся синхронизированными SQL СЕ-клиентами, стратегия RDA характеризуется низкими накладными расходами на сервере и хорошо масштабируется. Подобным образом с основным SQL-сервером может синхронизироваться неограниченное количество устройств с локальными базами данных SQL СЕ. Синхронизация данных реализуется с помощью специального механизма синхронизации SQL СЕ, который выполняется поверх Windows Internet Information Server (Web-сервер). Поскольку синхронизация основывается на Web-сервере, она при необходимости может осуществляться через общедоступную сеть. SQL-серверу ничего не известно о том, что клиентские базы данных должны синхронизироваться с его данными, поэтому ответственность за то, чтобы данные своевременно обновлялись на клиенте и сервере, лежит на мобильном приложении. Для получения более подробной информации относительно RDA прочитайте раздел справки "Using Remote Data Access" в материалах Microsoft "SQL Server СЕ Books Online"; эта документация поставляется как часть Visual Studio .NET (2003 или более поздняя версия). Резюмируя: RDA — суть низкие накладные расходы и отличная масштабируемость, но это дается за счет того, что данные приходится обновлять вручную. RDA — это прекрасный выбор в тех случаях, когда данные, которые должны синхронизироваться, главным образом используются только для чтения. 3. Синхронизация непосредственно с SQL-сервером. Этот механизм известен под названием репликации слиянием. При репликации слиянием между локальной базой данных SQL СЕ устройства и SQL-сервером, с которым она синхронизируется, устанавливаются партнерские отношения. Это — мощная модель, поскольку SQL-cepверу доподлинно известно, какие данные хранятся в каждой партнерской клиентской базе данных SQL СЕ; обновление данных, как на устройстве, так и на сервере, может осуществляться гораздо более автоматизированным и систематическим образом, нежели в случае синхронизации посредством RDA. Поскольку SQL-сервер должен сохранять информацию о каждом партнерском SQL CE- клиенте, эта модель масштабируется хуже, чем модель RDA; поддержка огромного количества клиентов будет ложиться тяжким бременем на сервер. Независимо от этого, если требуется обеспечить наиболее надежную синхронизацию, данный выбор великолепно для этого подойдет. Для получения более подробной информации относительно репликации данных слиянием прочтите раздел "Using Replication" в материалах Microsoft "SQL Server СЕ Books Online". Использование базы данных SQL СЕ несколькими приложениямиВ настоящее время SQL СЕ обеспечивает одновременную поддержку только одного соединения с любой отдельной базой данных. Это правило действует как внутри приложения, так и вне его. Каждая база данных хранится в отдельном файле; эти файлы нельзя открыть одновременно, используя SQL СЕ. Это означает, что хотя на одном и том же устройстве могут быть открыты одновременно несколько баз данных, любая конкретная база данных в любой момент времени может иметь только одно соединение. Если приложение пытается открыть файл базы данных SQL СЕ, который ранее уже был открыт другим или этим же приложением, то процессор базы данных сгенерирует исключение, и второе соединение установлено не будет. Если ваше приложение использует базу данных, которая не должна разделяться с другими приложениями, вам достаточно лишь убедиться в том, что ваш код не пытается установить одновременно более одного соединения с базой данных; соединением с базой данных следует управлять как глобальным ресурсом. Если ваше приложение работает с базой данных SQL СЕ, которая может использоваться совместно с другими мобильными приложениями, то вы должны учесть в своем проекте приложения два дополнительных момента: 1. Вы должны убедиться в том, что ваше мобильное приложение не удерживает открытым соединение с базой данных в течение большего времени, чем это крайне необходимо. Соединение следует устанавливать непосредственно перед тем, как возникнет потребность в доступе к базе данных, и по возможности освобождать сразу же после осуществления доступа к данным. Приложение должно проектироваться так, чтобы ему не требовался постоянный доступ к базе данных. 2. Вы должны предусматривать в коде защитные меры и быть готовыми к тому, что при любой попытке обращения к базе данных она уже могла быть до этого открыта. В вашем приложении должна быть предусмотрена модель, которая обеспечивает уведомление пользователя о том, что в настоящее время база данных уже используется другим локальным приложением, чтобы пользователь мог предпринять меры к закрытию другого приложения или вынудить его освободить соединение. Кроме того, в вашем мобильном приложении должна быть предусмотрена модель, позволяющая отложить доступ к базе данных на более поздний срок, когда установление соединения станет возможным; приложение не должно тормозиться из-за того, что не может подключиться к базе данных. База данных SQL СЕ доступна не на всех типах устройствВажно знать, что в настоящее время база данных SQL СЕ недоступна на смартфонах. Это связано с ограниченностью возможностей этих устройств в отношении, главным образом, размера базы данных, объема требуемой памяти и механизмов хранения данных. На устройствах Pocket PC имеются файловые системы на основе ОЗУ с питанием от батарей, обеспечивающие возможность быстрого доступа к файлам; смартфоны характеризуются тем, что для нужд долговременного хранения информации используется флэш-память, а объем рабочего ОЗУ небольшой, и оба эти фактора делают выполнение процессора базы на данном типе устройств менее желательным. В случае создания вами двух отдельных версий приложения, одна из которых предназначена для Pocket PC, а вторая — для смартфонов, вам придется продумать два варианта проектных решений. Приложение для смартфонов должно удовлетворять другим требованиям в отношении пользовательского интерфейса по сравнению с приложением для Pocket PC и располагает совершенно иными возможностями в отношении хранения данных. В случае приложений для смартфонов объем данных, хранимых в долговременном хранилище, обычно будет меньше, чем в случае приложений для Pocket PC. Приемлемым вариантом может служить использование SQL СЕ на устройствах Pocket PC и XML-файлов на смартфонах. Visual Studio .NET 2005 и SQL СЕ РезюмеКак и в случае задач повышения производительности, управления памятью и построения пользовательского интерфейса, создание удачной модели данных для мобильного приложения требует одновременно и планомерного подхода, и экспериментирования. Хорошая новость состоит в том, что многое из вашего опыта организации доступа к данным на настольных компьютерах вы сможете использовать при проектировании кода для доступа к данным в мобильных приложениях. Плохой же новостью является то, что вы сможете непосредственно использовать лишь небольшую часть уже имеющегося кода для настольных компьютеров, а для создания замечательных мобильных приложений вам придется учитывать специфику мобильных устройств. При организации доступа к данным самое важное — это определить, каким образом ваша стратегия доступа к данным будет удовлетворять потребности пользователей при работе в автономном режиме. Реалии таковы, что соединение между вашим мобильным приложением и серверами баз данных будут часто разрываться, иногда по причине того, что "так было задумано", а иногда — из-за сбоев в сети. Работе в условиях периодически разрывающихся соединений специально посвящена следующая глава, но этот момент является ключевым и при проектировании стратегии доступа к данным. Если пользователю требуется немедленный доступ к данным, они должны кэшироваться локально на устройстве. В зависимости от того, как будет использоваться ваше мобильное приложение, ему может потребоваться соединение с источниками данных посредством самых различных моделей подключения. Некоторые модели подключения, например Wi-Fi, отличаются высокой скоростью передачи данных и небольшой стоимостью, тогда как другие работают медленно и обладают высокой стоимостью. Дополнительные требования к разрабатываемому проекту могут появиться из-за необходимости поддержки соединений через общедоступные или виртуальные частные сети. В процессе проектирования модели доступа к данным для мобильного приложения важно представлять себе, какими могут быть сценарии подключения, и каким образом это может отразиться на ваших потребностях доступа к данным и их синхронизации. Важно продумать, какие данные будут храниться локально на устройстве, как будет организовано хранение этих данных и доступ к ним, и каким образом эти данные будут синхронизироваться с серверами. В средах программирования доступа к данным часто предлагают многоуровневые подходы для организации работы с данными. Как и при работе с XML-ориентированными средами, существуют низкоуровневые модели однонаправленного доступа к данным, которые не имеют состояния, и построенные поверх них полнофункциональные модели, хранящие очень подробную информацию о своем состоянии. ADO.NET предлагает возможность выбора между этими типами моделей. Как разработчик, вы можете работать либо на высоком уровне абстракции, используя объекты ADO.NET DataSet для управления данными в памяти, либо на низком уровне, используя непосредственно классы DataReader и DataConnection, которые напрямую связываются с базами данных. Как и на заправках, полный сервис — это, разумеется, неплоxo, но за все услуги надо платить; в случае доступа к данным дополнительной платой за использование высокоуровневых служб будет необходимость хранения состояния в памяти, а это, в конечном счете, означает снижение производительности. Если вы решите работать на низком уровне абстракции, то сможете хранить загруженные данные в наиболее эффективном для нужд вашего приложения формате, но тогда вам придется взять на себя все заботы по эффективному управлению данными. В случае данных небольшого объема, данных, которые требуют интенсивной поддержки динамического обновления или данных, характеризующихся сложными взаимосвязями, вам будет очень полезна полнофункциональная модель, основанная на использовании объектов ADO.NET DataSet. При работе с объектами DataSet убедитесь в том, что вы используете наиболее эффективные способы доступа к данным. В случае работы с объектами DataRow в объектах DataTable это означает использование кэшированных индексов объектов DataColumn для доступа к полям. Для достижения максимально возможной производительности при работе с большими объемами данных вы должны продумать для своего приложения пользовательскую модель данных, в наибольшей степени оптимизированную под решаемую задачу. Результатом этого может быть как непосредственное повышение производительности, так и снижение общего объема памяти, потребляемой вашим приложением. Если вы остановились на пользовательском низкоуровневом подходе, то по возможности постарайтесь воспользоваться наиболее простой и эффективной в отношении использования памяти моделью. Всегда осуществляйте мониторинг выполнения кода и тестируйте производительность вашего варианта проекта по сравнению с существующими высокоуровневыми моделями доступа к данным! Существует две рекомендованных модели локального хранения долговременных данных на устройствах, одна из которых предполагает хранение данных в виде XML-файлов, а вторая — использование локальной базы данных устройства, например SQL СЕ. Каждый из этих вариантов доступен как при использовании высокоуровневой модели ADO.NET DataSet, так и при использовании адаптированных низкоуровневых механизмов для работы с данными. Коль скоро объем данных, с которыми приходится работать, остается сравнительно небольшим (например, порядка 50 Кбайт в случае XML-данных), то отличные и гибкие возможности вам предоставят XML-файлы. С увеличением же объемов данных все более привлекательным будет становиться использование процессоров баз данных. И вновь следует подчеркнуть, что единственным способом проверки того, что вы приняли верные проектные решения, является мониторинг выполнения кода и получение количественных показателей, которые можно сравнивать между собой. Как и в случае проектирования пользовательских интерфейсов, лозунг "пишется однажды — выполняется везде" — не более чем призрачная цель при проектировании доступа к данным в мобильных приложениях. Для достижения максимально возможной производительности вы должны специальным образом настраивать модели доступа к данным и использования памяти применительно к конкретным устройствам, на которых будет выполняться приложение. Если вы создаете несколько версий приложения, ориентированные на различные классы устройств, то вам, вероятно, придется выбрать для каждого класса устройств свою модель хранения данных, зависящую от возможностей устройства и потребностей приложения. В случае современных мобильных устройств, обладающих широчайшими возможностями, применение технологий доступа к данным является не только необходимым, но и чрезвычайно плодотворным. Выбор наиболее подходящей модели, способной удовлетворить потребности вашего приложения и в то же время оставаться достаточно гибкой, чтобы ее можно было настраивать в соответствии с требованиями реальной практики, является увлекательнейшей задачей проектирования. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||