|
||||||||||||||||
|
|
ГЛАВА 3Внутренняя структура .NET Compact Framework
ВведениеВ этой главе предлагается концептуальное объяснение принципов функционирования .NET Compact Framework и других сред времени выполнения управляемого кода. Благодаря этому разработчики, создающие приложения для мобильных устройств на основе управляемого кода, будут хорошо представлять себе, каким образом их приложения работают в средах с управляемым кодом. Тем, кто создает приложения с использованием собственных кодов, знание стратегий проектирования, применяемых в средах времени выполнения управляемого кода, поможет создавать приложения для мобильных устройств, отличающиеся высоким быстродействием и экономным расходованием памяти. Вообще говоря, программное обеспечение, созданием которого занято большинство разработчиков, можно разделить на три категории: ■ Приложения. Приложение (application) представляет собой компьютерную программу, с которой взаимодействует конечный пользователь. Эта программа либо запускается для обслуживания конкретных запросов конечного пользователя, либо предоставляет услуги конечным пользователям. Проектные решения принимаются исходя из того, насколько полезными они будут для конечного пользователя. В данной книге под "приложениями" будут пониматься графические приложения с развитым пользовательским интерфейсом. ■ Повторно используемые компоненты. Повторно используемые компоненты (reusable components) представляют собой модульные фрагменты кода, которые разработчики могут использовать для ускорения процесса создания приложений. При создании компонентов проектные решения принимаются исходя из того, чтобы облегчить их повторное использование разработчиками, создающими приложения. С точки зрения технической, в отношении проектного формализма компоненты занимают промежуточную позицию между приложениями и каркасами приложений. Повторно используемые компоненты могут быть либо графическими, либо "безликими", в том смысле, что в них отсутствует код пользовательского интерфейса. Типичные компоненты содержат несколько крупных основных классов, для поддержки которых предусматриваются меньшие классы. Хорошим примером повторно используемых компонентов может служить модуль построения графических диаграмм. Один и тот же хорошо спроектированный модуль может использоваться одновременно несколькими различными приложениями. В таком модуле может иметься один "диаграммный" класс и несколько меньших вспомогательных классов, представляющих такие характеристики диаграмм, как отображаемые данные, информация об осях и цветовые параметры линий диаграмм. ■ Каркасы приложений. Каркасы, или скелеты (остовы) приложений (frameworks) — это формализованные, тщательно спроектированные и организованные деревья объектов. Каркасы приложений призваны играть роль фундамента, на котором можно строить приложения и компоненты. При создании каркасов приложений значительные усилия направляются на разработку логической организации деревьев объектов, содержащихся в каркасе, чтобы в своей совокупности они составляли одно взаимосвязанное целое. Это объясняется тем, что каркасы приложений должны упрощать решение как можно более широкого круга задач программирования. Обычно каркасы состоят из многочисленных классов небольшого или среднего размера, которые разработчики могут многократно использовать для решения стоящих перед ними задач. Хотя граница, разделяющая каркасы приложений и компоненты, довольно условна, компонентами, как правило, считаются программные единицы, которые удовлетворяют конкретные потребности приложений, тогда как к каркасам приложений обычно относят более универсальные наборы инструментов проектирования. Примером среды, ориентированной на разработку приложений на основе каркасов приложений, является .NET Compact Framework. В действительности .NET Compact Framework представляет собой нечто большее, чем просто каркас для создания приложений. Это одновременно и программный каркас (programming framework), который разработчики могут использовать для создания мобильных приложений, компонентов и высокоуровневых каркасов, и исполнительный механизм (execution engine), который может получать откомпилированные приложения и запускать их в управляемой среде выполнения. Для этого исполнительного механизма существует и другое распространенное название — среда времени выполнения (runtime). Поскольку платформа .NET Compact Framework сама была создана как проект разработки программного обеспечения для мобильных устройств, имеет смысл ближе познакомиться с целями и философией, которые положены в основу этого проекта. Знание ответов на приведенные ниже вопросы будет полезно как разработчикам приложений, так и разработчикам архитектур программного обеспечения. ■ На обеспечении каких возможностей остановили свой выбор разработчики платформы, и какие проектные решения были приняты в процессе разработки .NET Compact Framework? Несмотря на наличие между ними множества общих черт, каждая из сред времени выполнения для мобильных устройств имеет свои особенности, зависящие от возможных сценариев использования конечного продукта, на которые ориентировался проект. Все среды времени выполнения, предназначенные для мобильных устройств, оптимизируются для эффективного выполнения программ небольшого размера, но для каждой из технологий сред выполнения существуют определенные области, в которых с целью расширения набора функциональных возможностей приходится сознательно идти на увеличение размера программ и объема потребляемых ресурсов. Соответствующие знания будут полезны как разработчикам приложений, так и разработчикам системных архитектур, которые должны принимать решения относительно того, какие возможности мобильной среды времени выполнения, выбранной для разработки, могут им понадобиться, будь то .NET Compact Framework, J2ME или любая другая среда времени выполнения для мобильных устройств. ■ В частности, какова архитектура .NET Compact Framework? Ответ на этот вопрос будет интересовать тех разработчиков приложений и системных архитектур, которые планируют создавать каркасы приложений на основе управляемых сред времени выполнения, поскольку это облегчит им понимание того, какие аспекты проектирования с использованием сред времени выполнения для мобильных устройств являются ключевыми. ■ Какие характеристики важны для достижения максимальной производительности приложений, компонентов и каркасов, построенных на основе .NET Compact Framework? Это представит интерес для каждого разработчика, использующего для создания кодов управляемую среду времени выполнения .NET Compact Framework. Как проектировалась .NET Compact FrameworkЗалогом успешного решения любой технической задачи является предварительное определение общих целей, к достижению которых следует стремиться в процессе работы над проектом. Было бы неправильно сказать, что все основные идеи, относящиеся к проекту .NET Compact Framework, зародились в одной голове, поскольку это не соответствовало бы действительности. Идеи проекта .NET Compact Framework явились результатом бурных споров между основными участниками группы разработки инструментальных средств и сред выполнения, каждый из которых горячо отстаивал свое мнение. Одни из них придерживались той точки зрения, что самое главное — это добиться максимально возможного уменьшения размера кода. Другие ставили во главу угла обеспечение межплатформенной совместимости кода. Часть членов группы считала, что ключом к завоеванию рынка будет создание прикладных систем уровня предприятия для Pocket PC. Каждая из этих идей тщательно изучалась, сопоставлялась с другими идеями и сразу же апробировалась в ходе лабораторных испытаний, проводимых группой целевых разработчиков. Благодаря сотрудничеству с независимыми разработчиками, которые в ходе указанных лабораторных испытаний использовали уже самые первые из созданных нами кирпичиков для построения реальных мобильных приложений, нам удалось многое выяснить относительно того, что именно является наиболее важным, обязательно необходимым или же просто желательным для сред времени выполнения, ориентированных на мобильные устройства. Эта обратная связь определяла наши действия на протяжении всей первой фазы нашего многолетнего процесса разработки, и мы глубоко благодарны всем тем, кто предоставил нам бесценную информацию, выполняя тестирование первоначальных результатов нашего труда. Их независимые суждения позволили нам уточнить, доработать и отшлифовать базовые принципы, которые следовало использовать для доведения проекта до его полного завершения. После согласования основных целей проекта началась вторая фаза процесса разработки, обеспечившая практическую реализацию этих идей, их уточнение, а в необходимых случаях и внесение поправок в промежуточный продукт для достижения разумного компромисса между взаимно конкурирующими требованиями к размеру, производительности и возможностям программного кода. Увенчавшим наши усилия конечным результатом в виде версии 1.1 платформы .NET Compact Framework мы были весьма удовлетворены. В случае мобильных устройств описанный итеративный характер процесса проектирования играет особенно важную роль по той причине, что в разработке программного обеспечения для устройств накоплен пока еще гораздо меньший опыт, чем в случае настольных компьютеров или серверов. Мобильные устройства стали использоваться в качестве гибких прикладных платформ сравнительно недавно, и многие разработчики только пытаются разглядеть свой путь при слабом утреннем свете нового дня; итеративный подход с учетом обратной связи с пользователями приобретает в этих условиях особое значение. К вопросу о том, как придать итеративный характер процессу проектирования, мы будем постоянно возвращаться на протяжении всей этой книги. Ниже, в порядке уменьшения степени важности, перечислены основные критерии, которым должна была удовлетворять первая версия .NET Compact Framework. 1. .NET Compact Framework необходимо было создавать как подмножество разработанной ранее для настольных компьютеров и серверов среды .NET Framework, совместимое с последней па уровне двоичных кодов и удовлетворяющее требованиям стандартов. На разработку среды .NET Framework, ориентированной на настольные компьютеры и серверы, были затрачены большие усилия, и не воспользоваться достигнутыми результатами было бы просто глупо. К тому же, значительная часть этих результатов, включая двоичный формат откомпилированных приложений (IL), язык программирования С# и библиотеки базовых классов программного каркаса, уже была подана на рассмотрение в органы стандартизации (ЕСМА-334 и ЕСМА-335, ISO/IEC 23270 (С#), ISO/IEC 23271 (CLI) и ISO/IEC 23272) и утверждена. При создании .NET Compact Framework ставилась явная задача реализации этих стандартов, а вместе с этим и использования языковых компиляторов .NET. Возможность использования уже прошедших всестороннюю апробацию и доказавших свою работоспособность компиляторов С# и VB.NET для создания приложений на платформе .NET Compact Framework наряду с привлечением большого количества инструментальных средств проектирования, тестирования и отладки, уже доступных для разработки программного обеспечения на настольных компьютерах и серверах, делали этот путь гораздо более надежным и технически эффективным, чем разработка нового варианта реализации указанных средств с нуля. 2. Межплатформенные возможности. Хотя первые реализации среды .NET Compact Framework предназначаются для операционных систем Pocket PC, Windows CE и Microsoft Smartphone, сама она была спроектирована таким образом, чтобы при необходимости ее можно было переносить на другие платформы. Одним из практических следствий такого проектного решения является тот факт, что все вызовы из .NET Compact Framework, затрагивающие базовую операционную систему, осуществляются через единый интерфейс — PAL (platform abstraction layer — уровень абстракции платформы). Это упрощает учет зависимостей базовой операционной системы в процессе проектирования и облегчает задачу переноса среды времени выполнения и библиотек в другие операционные системы. Отсюда вовсе не следует, что перенос программного обеспечения в другую операционную систему не будет представлять никакой сложности лишь по той единственной причине, что этот аспект был учтен в процессе проектировании .NET Compact Framework. Например, в некоторых операционных системах часть функциональных средств, на которые отображается PAL, может отсутствовать, в связи с чем необходимо, чтобы PAL для этой платформы реализовал такие возможности, как многопоточное выполнение, управление памятью, создание графических объектов или иную функциональность, которую целевая операционная система предоставить не может. Решение подобной задачи может оказаться весьма непростым, но оно сводится к хорошо известному и проверенному процессу, который не был упущен из виду в процессе проектирования .NET Compact Framework. 3. Мощные возможности клиентской стороны, включая поддержку рисования и форм, выполнение функций клиента Web-служб и предоставление модели доступа к данным, обладающей широкими возможностями. Мы пришли к выводу, что для того, чтобы среда времени выполнения для устройств воспринималась разработчиками прикладных программ как конкурентоспособная, она должна удовлетворять нескольким ключевым требованиям. Прежде всего, требовалось, чтобы она обеспечивала создание пользовательских интерфейсов с широким набором возможностей, предоставляющих современные элементы управления, к которым разработчики уже успели привыкнуть (например, сетки, списки и древовидные представления). Далее, она должна была обеспечивать ту же простоту использования Web-служб приложениями, что и в случае .NET-приложений, выполняющихся на настольных компьютерах (то есть делать эту задачу тривиальной) Кроме того, она должна была предоставлять современную, расширяемую модель для работы с базами данных (ADO.NET), обеспечивающую самые широкие возможности. Поддержка всех вышеперечисленных средств была реализована в библиотеке объектов .NET Compact Framework. 4. Низкие требования к объему установленной на устройстве и занимаемой платформой памяти. Для того чтобы иметь практические шансы пробиться на массовый рынок устройств с типичными размерами образов ПЗУ (ROM images), наша система должна была занимать не более 2 Мбайт памяти. Возможность размещения в образе ПЗУ с типичным для массовых устройств объемом рассматривалась нами как неотъемлемая характеристика платформы для мобильных устройств. Чтобы облегчить решение этой задачи, не менее важно было обеспечить возможность установки платформы в файловых системах ОЗУ существующих устройств таким образом, чтобы оставалось еще достаточно много места для приложений и данных. Для решения обеих задач требовалось, чтобы необходимый для платформы объем памяти, используемой на устройстве, не превышал 2 Мбайт. Кроме того, .NET Compact Framework должна была сохранять работоспособность и в средах, в которых действуют жесткие ограничения в отношении доступных объемов ОЗУ. Эти цели значительно отличаются от тех, которые ставились при разработке платформы .NET Framework для настольных компьютеров и серверов, ориентированной на выполнение в условиях сред с достаточными запасами ресурсов, когда достижение максимальной пропускной способности имело намного более высокий приоритет по сравнению с минимизацией объема памяти, занимаемого платформой. 5. Требовалось предоставить практическую поддержку, по крайней мере, двух языков .NET — С# и Visual Basic .NET. Хотя с теоретической точки зрения коды на любом из языков программирования, ориентированных на стандартизированное подмножество байтовых кодов IL и стандартизированное множество библиотек программ .NET Compact Framework (ЕСМА и ISO), должны быть способными к компиляции для выполнения на платформе .NET Compact Framework, это необходимо было подтвердить на практике путем фактической реализации нескольких языков. Мы выбрали языки С# и Visual Basic, поскольку они являются наиболее популярными языками .NET. Как и в случае варианта реализации для настольных компьютеров и серверов, это подразумевало включение в .NET Compact Framework библиотеки времени выполнения Microsoft.VisualBasic.DLL. 6. Платформа должна была служить удобной заменой собственных кодов для большинства приложений коммерческого, научного, производственного и развлекательного характера. Было очень важно, чтобы разработчики программного обеспечения для настольных компьютеров и серверов не испытывали никаких неудобств в работе или ограничений с точки зрения синтаксиса при переходе к платформе .NET Compact Framework. Если бы эта цель не была достигнута, то количество разработчиков указанной категории, пожелавших совершить такой переход, было бы значительно меньше, нежели то, на которое мы рассчитывали. Такой урок можно было извлечь из предыдущих попыток создания сред времени выполнения, ориентированных на устройства, которым не удалось достигнуть "критической массы". Как проект Embedded Visual Basic компании Microsoft, так и аналогичные проекты других компаний не оправдали ожиданий, поскольку в них не был предусмотрен ряд ключевых возможностей, которые обычно используются при создании программного обеспечения для настольных компьютеров и серверов или в случае применения собственных кодов при разработке программного обеспечения для устройств. Мы исходили из того, что при любой успешной замене подхода, основанного на использовании собственных кодов, любой другой предлагаемый подход должен поддерживать следующие возможности: • Арифметические операции с плавающей точкой, вычисление тригонометрических и трансцендентных функций. С точки зрения разработчиков для настольных компьютеров и серверов включение этих средств представляется само собой разумеющимся, но с позиций разработки программного обеспечения для устройств это отнюдь не самоочевидно. В силу причин, обусловленных факторами размеров, стоимости и энергопотребления, процессоры многих мобильных устройств не имеют встроенной поддержки арифметических операций с плавающей запятой. Вместо этого данная функциональность обеспечивается библиотеками программ, выполняющимися поверх процессоров. Мы пришли к выводу, что хотя большинство алгоритмов основаны на целочисленной арифметике, почти для любого реального приложения всегда найдутся случаи, когда без операций с десятичными числами обойтись невозможно. Рассмотрение всего того, что может потребоваться для проведения финансовых расчетов (например, с целью определения размеров процентных ставок или построения диаграмм), научных расчетов или же расчетов, связанных с играми, убедило нас в том, что попытка заменить использование собственных кодов для мобильных устройств подходом, основанным на управляемом коде, может быть успешной лишь в том случае, если при этом будет обеспечена поддержка операций с плавающей запятой. • Все базовые элементы языков программирования и широко используемые библиотеки программ. Мы не могли исключить ни такие предоставляемые любым современным объектно-ориентированным языком программирования возможности, как механизм наследования или обработка структурных исключений, ни такие низкоуровневые библиотечные функции, как функции ввода-вывода файлов, основанные на потоках. Разработчик рассчитывает на то, что эти средства программирования будут всегда находиться у него под рукой, и в случае их отсутствия у него возникает чувство, будто его лишили самого необходимого, тогда как он должен всегда работать в комфортных условиях и быть во всеоружии. 7. Возможность доступа к средствам базовой операционной системы, если в этом возникает необходимость. Осознав всю важность фактора межплатформенной переносимости, мы поняли, что разработчики не должны быть ограничены доступом только к тем средствам, которые были нами первоначально запланированы. Наша основная задача заключалась в том, чтобы предоставить разработчикам удобное подмножество средств платформы .NET Framework, предназначенной для настольных компьютеров, которое было бы пригодным для создания тех видов приложений, о которых говорили сами разработчики, однако можно было предполагать, что неизбежно возникнут случаи, когда предусмотренной нами функциональности разработчикам окажется мало. Какой смысл в том, чтобы предоставлять разработчику возможность создать 90 процентов мобильного приложения с использованием управляемого кода, если он зайдет в тупик из-за недостатка необходимых средств при создании остальных 10 процентов приложения. Поэтому предоставление разработчикам удобного способа, обеспечивающего возможность вызова собственных кодов, было сочтено важным фактором, позволяющим разработчикам обойти трудности, связанные с отсутствием в .NET Compact Framework той или иной функциональности. Вот четыре примера: в настоящее время вызовы собственных кодов (или поставляемых независимыми разработчиками библиотечных функций, служащих оболочками для вызовов собственных кодов) нужны для явного управления сетевыми соединениями, набора телефонных номеров, воспроизведения звука и доступа к API-интерфейсам шифрования; эти функциональные возможности требуются далеко не каждому разработчику, но те, кому они действительно необходимы, будут чувствовать себя стесненными в своих действиях, если не смогут получить доступ к указанным средствам из-за невозможности использования вызовов собственных кодов Чем объясняется присвоение первому выпуску NET Compact Framework номера версии 1.1, а не 1.0? .NET Compact Framework как подмножество платформы для настольных компьютеровПриступая к проектированию .NET Compact Framework, мы знали, что в конечном счете должны получить некое совместимое подмножество среды .NET Framework, предназначенной для настольных компьютеров, которое удовлетворяло бы требованиям разработчиков. Вопрос о том, каким именно образом следовало определить это подмножество, стал предметом серьезного обсуждения. Следует ли отталкиваться от платформы .NET Framework, постепенно исключая из нее все то, что не нужно, или же лучше начать проектирование новой платформы с нуля, включая в нее только те средства, которые являются действительно необходимыми? Будучи не в состоянии решить эту философскую дилемму, мы остановились на том, чтобы использовать оба подхода и посмотреть, какой из них окажется более приемлемым. Такой способ действий требовал большего времени и ресурсов, однако, по моему мнению, только с его помощью и можно было окончательно разрешить указанные разногласия. Действуя в направлении сверху вниз, мы могли определить максимальный состав тех ключевых возможностей, поддержку которых мы хотели бы обеспечить, тогда как подход, соответствующий продвижению снизу вверх, позволял нам составить хорошее представление о том, какой может быть минимальная реализация и как влияет на размерные показатели и производительность добавление тех или иных возможностей. (Ради справедливости замечу, что лично я принадлежал к числу тех проигравших участников дебатов, которые рекомендовали использовать для создания библиотек программ разработку в направлении сверху вниз. Эта модель оказалась полезной в отношении понимания того, что же именно мы хотим создать, но не могла обеспечить необходимую производительность. Единственным путь, гарантирующий достижение этой цели, был связан с осуществлением разработки по принципу "снизу вверх".) В конце концов, ситуация с определением наиболее оптимального варианта решения значительно прояснилась. Единственным способом достижения максимальной производительности при сохранении приемлемого размера платформы была ее разработка с нуля и постепенная достройка в направлении снизу вверх путем постепенного добавления только тех типов, классов, методов и свойств, введение которых было необходимым или оправданным. Но даже при таком подходе объем платформы намного превышал тот, который первоначально предсказывался большинством участников группы, хотя полученное решение и отличалось ясностью и оптимальностью. Мне кажется, что отсюда можно сделать один общий вывод: при проектировании подмножеств каркасов, компонентов или приложений для мобильных устройств на основе версий, предназначенных для настольных компьютеров или серверов, для получения прототипов на ранних стадиях разработки целесообразно отталкиваться от имеющихся версий, постепенно исключая из них те или иные элементы для получения лучшего представления о том, какой именно результат вы хотите получить; однако если речь идет о фактической реализации, то наиболее ясное и хорошо проработанное решение обеспечивается разработкой в направлении снизу вверх. В процессе анализа мыслите, переходя от более общих категорий к менее общим, тогда как в процессе реализации начинайте с разработки мелких деталей, постоянно оценивая эффективность каждого своего шага. Управляемый код и собственный кодРазмер кода большинства приложений значительно меньше размера выполняющегося под ним кода среды времени выполнения и операционной системы. Особенно это касается приложений с графическим пользовательским интерфейсом, при создании которых разработчик имеет дело с высокоуровневыми абстракциями, в то время как значительную часть остального выполняющегося кода составляет низкоуровневый библиотечный код, обеспечивающий функционирование пользовательского интерфейса. Отсюда становится очевидным, насколько важную роль играет хорошо спроектированная и высокопроизводительная среда времени выполнения. При проектировании сред выполнения управляемого кода возможны два подхода: 1. Реализация как можно большей части среды времени выполнения и библиотек программ с использованием собственных кодов и последующее создание тонкого интерфейсного слоя управляемого кода, обеспечивающего доступ разработчиков приложений и компонентов к этой части. Привлекательной стороной такого подхода является то, что он позволяет добиться максимально высокой производительности, а отрицательной стороной — сложность и потенциально более низкая надежность среды выполнения, которая в этом случае не использует всех преимуществ, предоставляемых выполнением полностью управляемого кода. 2. Реализация с использованием собственных кодов лишь в самых необходимых случаях, тогда как вся остальная функциональность обеспечивается применением управляемого кода. Такой подход может улучшить характеристики переносимости и надежности и позволяет выжать из исполнительного механизма управляемого кода максимально возможную производительность, поскольку этот механизм будет использоваться подавляющей частью кода. Везде, где только это было возможно, функциональность .NET Compact Framework реализовывалась за счет управляемого кода; с использованием собственных кодов написано лишь 20-30 процентов общего объема кода .NET Compact Framework. Для написания всех библиотек программ применялся управляемый код. Лишь сам исполнительный механизм и небольшая часть графической подсистемы написаны с использованием собственных кодов. Использование управляемого кода во всех библиотеках программ позволяет осуществлять их загрузку и компиляцию, а также управление памятью теми же методами, что и в случае любых других библиотек. Схема логического разделения .NET Compact Framework на отдельные составляющие, написанные с использованием управляемого и собственного кодов, представлена на рис. 3.1. 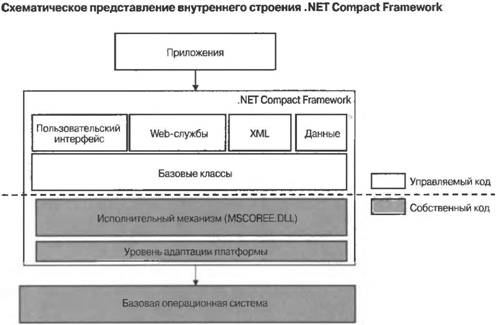 Рис. 3.1. Компоненты .NET Compact Framework, написанные с использованием собственного и управляемого кодов Исполнительный механизмИсполнительный механизм NET Compact Framework представляет собой низкоуровневый код, отвечающий за загрузку, JIT-компиляцию и выполнение управляемого кода, а также управление памятью. Ему приходится брать на себя всю черновую работу, обеспечивающую выполнение управляемого кода. Исполнительный механизм написан на языках C/C++ и компилируется в собственные команды процессора. На этот механизм дополнительно возлагается задача трансляции .NET Compact Framework и приложений конечного пользователя в исполняемый формат во время выполнения. Этот процесс известен под названием JIT- компиляции (just-in-time — оперативная). С помощью этого же механизма обрабатываются любые переходы из управляемого кода в собственный код, например, вызовы функций основанного на собственном коде API-интерфейсов базовой операционной системы; этот процесс называется переключением (thunking). Поскольку именно исполнительный механизм осуществляет обработку любого низкоуровневого взаимодействия с базовой операционной системой, значительная доля усилий на стадиях проектирования и тестирования направляется на то, чтобы сделать этот механизм как можно более надежным. Библиотеки управляемого кодаБиблиотеки управляемого кода .NET Compact Framework являются той программной частью, с которой взаимодействуют разработчики. Как и в случае варианта .NET Framework для настольных компьютеров, библиотеки .NET Compact Framework размещены в нескольких DLL-файлах. Эти библиотеки присутствуют на настольных компьютерах во время проектирования, а также устанавливаются на целевых устройствах для использования во время выполнения. Для работы с этими библиотеками во время проектирования используются имена System.DLL, Systems.Windows.Form.DLL и System.Xml.DLL. На устройствах эти файлы могут иметь другие имена в зависимости от потребностей целевых устройств, связанных с именованием и учетом версий файлов. В процессе компиляции библиотеки управляемого кода используются аналогично тому, как заголовочные файлы используются компиляторами C/C++ или библиотеки типов используются прежними (полученными с применением VB6 и более ранних версий) кодами на языке Visual Basic для передачи информации об интерфейсах и типах, используемых компилируемым кодом. Тот факт, что эти файлы имеют то же DLL-расширение, что и файлы библиотек собственных кодов C/C++, объясняется исключительно желанием сохранить привычный подход к именованию файлов; природа их двоичного содержимого совершенно другая, и в состав их имен с равным успехом может быть включено любое другое удобное расширение. То, что имена файлов .NET Compact Framework обычно совпадают с именами соответствующих файлов .NET Framework, также объясняется только соображениями удобства. В действительности эти файлы могут быть дополнительно разделены на еще большее количество файлов или объединены в один файл, если в этом возникнет необходимость. В будущих реализациях для систем, отличных от Windows, может быть выбран именно такой вариант, если это окажется более предпочтительным. Обычно детали реализации в приложениях учитываться не должны, поскольку задачи поиска, загрузки и управления общими библиотеками, присутствующими на устройстве, решаются средой времени выполнения. С точки зрения программирования каждый из этих DLL-файлов предоставляет разработчику набор иерархических пространств имен, содержащих классы и типы. Примерами пространств имен, содержащих классы и типы, могут служить: System.* System.Xml.* System.Data.* System.Drawing.* и тому подобные. DLL-файлы и пространства имен связаны между собой отношениями типа "многие ко многим"; один DLL-файл может предоставлять имена сразу для нескольких пространств имен (например, если это потребуется, файл Foo.DLL может содержать типы, относящиеся как к пространству имен MyNamespace.*, так и к пространству имен SomeOtherNamespace.SomethingElse.*), а несколько DLL-файлов могут предоставлять имена для одних и тех же пространств имен (например, при необходимости одновременно оба файла Foo.DLL и Bar.DLL могут предоставлять типы для пространств имен MyNamespace.* и SomeOtherNamespace.SomethingElse.*). Во время компиляции приложения компилятору передается набор имен файлов, подлежащих просмотру с целью поиска классов и типов, которые пользователь намеревается применять в своем приложении; эти имена принято называть ссылками (references). Если в коде разработчика или библиотеках, на которые имеются ссылки, некоторые типы/методы/свойства найти не удается, генерируется сообщение об ошибке времени компиляции. Кроме того, в случае обнаружения нескольких версий типов в разных библиотеках также генерируется сообщение об ошибке времени компиляции, связанной с неоднозначностью определения типа. Во всех остальных случаях, не связанных с периодом компиляции, когда компилятору предоставляется список файлов, используемых для поиска классов, на которые имеются ссылки, разработчикам можно не беспокоиться о том, в каком файле находится тот или иной класс. Вместо этого они должны думать лишь о логической иерархии используемых пространств имен, тогда как вопрос о фактическом размещении конкретных типов в указанных файлах их заботить не должен. Библиотеки базовых классовБазовые классы — это квинтэссенция программирования. В них содержатся распространенные типы и функциональность, которые используются разработчиками при реализации большинства алгоритмов обработки данных. Базовые классы имеют следующий состав: ■ Все основные типы данных, к которым, например, относятся целые числа, строки, числа с плавающей запятой, дата/время, массивы и коллекции. ■ Средства файлового ввода-вывода, потоки, сетевые сокеты. ■ Средства поиска типов, методов и свойств в сборках и привязки к ним во время выполнения. Эти возможности называют отображением (reflection). ■ Средства, позволяющие учитывать в приложениях региональную и местную специфику. Эти возможности называют глобализацией (globalization). Вышеперечисленные функциональные возможности вместе с дополнительными базовыми классами инкапсулированы в следующих иерархических пространствах имен: System.* System.Collections.* System.ComponentModel.* System.Diagnostics.Globalization.* System.IO.* System.Net.Sockets.* System.Security.* System.Text.* System.Threading.* Библиотеки пользовательского интерфейсаПри создании библиотек пользовательского интерфейса преследовались две цели: 1) предоставить разработчикам возможность создавать многофункциональные приложения уровня предприятия с использованием таких современных высокоуровневых элементов управления пользовательского интерфейса, как Button, PictureBox, ListView, TreeView, TabControl и так далее, и 2) предоставить разработчикам возможность выполнения низкоуровневых операций рисования на мобильных устройствах с использованием расширенного набора операций для обработки растровых изображений, позволяющего рисовать такие, например, двумерные объекты, как линии, многоугольники, текст и изображения. Описанные функциональные возможности предлагаются в двух иерархических пространствах имен: ■ System.Drawing.* — средства создания двумерных рисунков. ■ System.Windows.* — элементы управления пользовательского интерфейса и вспомогательные функциональные средства. Библиотеки клиентов Web-службWeb-службы — стандартный способ организации связи между приложениями, выполняющимися на различных платформах. По существу, сервер Web-службы — это Web-сервер, предоставляющий приложениям программные интерфейсы, для доступа к которым в качестве языка общения используется XML. Синтаксис такого общения на языке XML определяется протоколом SOAP, название которого представляет собой аббревиатуру от Simple Object Access Protocol — простой протокол доступа к объектам. Клиент Web-службы — это приложение, которое может осуществлять вызовы с целью создания запросов, посылаемых серверам Web-служб, и интерпретировать получаемые ответные сообщения SOAP. Для описания предоставляемых интерфейсов серверы Web-служб в ответ на соответствующий запрос возвращают WSDL-документы. WSDL — это аббревиатура от Web Service Description Language (язык описаний Web-служб), и, подобно SOAP, этот язык представляет собой синтаксис, построенный поверх XML. WSDL описывает предоставляемый Web-службой программный интерфейс; для создания запросов этих интерфейсов используется протокол SOAP. Ключевой особенностью платформы .NET Framework для настольных компьютеров и серверов, равно как и инструмента разработки Visual Studio .NET, является простота создания Web-служб и получения соответствующих услуг. В Visual Studio .NET предусмотрена возможность синтаксического анализа WSDL-документов и генерации простых в использовании клиентских классов-заместителей (proxy classes), при помощи которых разработчики могут получать доступ к Web-службам. Благодаря наличию упомянутых классов-заместителей вызов Web-службы концептуально сводится к простой процедуре создания объекта и вызова его метода. При проектировании .NET Compact Framework специально ставилась задача поддержки достаточно многофункционального набора классов, свойств и методов, обеспечивающих компиляцию вышеупомянутых клиентских классов-заместителей, автоматически генерируемых Visual Studio .NET. Эта задача была успешно решена, и теперь организовать работу приложений на мобильных устройствах в качестве клиентов Web-служб столь же просто, как и в случае их аналогов, выполняющихся на настольных компьютерах и серверах. Функциональные средства этой категории предоставляются пространством имен System.Net.*. Библиотеки XMLПочему XML придается настолько большое значение? Чтобы в этом разобраться, необходимо рассмотреть все "за" и "против" двух способов обмена данными между приложениями, использующих, соответственно, двоичный и текстовый форматы данных. Обмен двоичными данными требует соблюдения всеми сторонами строгих договоренностей относительно способа форматирования и интерпретации данных. Двоичные форматы требуют тщательного планирования управления их версиями всеми сторонами, использующими эти форматы. Все это значительно снижает гибкость данного метода; любое изменение двоичного формата, которое предварительно не было согласовано со всеми сторонами, приведет к нарушению работы приложений, использующих эти данные. Как бы в качестве компенсации этого недостатка, двоичные форматы предлагают возможность более компактного представления данных. Тем самым обеспечивается снижение расхода памяти и увеличение скорости обработки данных. Решение, которое традиционно обеспечивали текстовые файлы, совершенно противоположно по своему характеру: оно повышает гибкость взаимодействия между различными сторонами за счет использования более свободных договоренностей между ними и более подробного описания формата кодирования данных. В качестве метода хранения простых данных и организации обмена ими XML заменил традиционные текстовые файлы во многих областях применения. XML-файлы представляют собой обычные текстовые файлы, отличающиеся тем, что в них содержится дополнительная информация относительно собственной структуры. Это позволяет упростить их обработку стандартными способами и облегчает их повторное использование. Разработчики останавливают свой выбор на текстовых форматах по той причине, что с ними проще работать, ибо они более терпимы к изменениям схемы организации данных и облегчают учет специфики различных версий. XML поднимает текстовый способ хранения данных на более высокий уровень. XML предлагает достижение разумного компромисса между чрезмерно сложным и чрезмерно упрощенным подходами к структуризации информации. Такое наполовину структурированное хранение данных обеспечивает значительные преимущества по сравнению с обычными текстовыми файлами. Данные сохраняются в иерархическом текстовом формате с использованием дескрипторов (tags), предоставляющих информацию о структуре содержимого. Например, информация о шрифте может быть сохранена посредством фрагмента текста <Font> ххх </Font>, который позволяет приложению, интерпретирующему текст, легко определить, что означает этот элемент данных. Приложения, работающие с XML-данными, могут выбирать лишь те порции текста, которые представляют для них интерес или смысл которых для них понятен. Таким образом, XML является важным усовершенствованием по сравнению с предыдущими текстовыми форматами, такими как файлы *.INI, контейнеры PropertyBag или HTML-текст, так как обеспечивает одновременно и больший объем структурной информации, и большую гибкость. Поскольку в настоящее время XML очень широко используется в качестве средства обмена информацией, наличие его поддержки является весьма важной характеристикой любой современной программной среды. Не будь ее, каждый разработчик был бы вынужден самостоятельно писать собственные наборы функций для синтаксического анализа текстовых файлов и извлечения или сохранения необходимых данных. Такое решение было бы крайне неэффективным и значительно увеличило бы вероятность появления в приложениях ошибок, которых можно было бы избежать. Поскольку большинство разработчиков заняты созданием приложений, а не синтаксических анализаторов, "самодеятельные" варианты реализации обычно способны выполнять то, что требуется, лишь в минимальном объеме и почти во всех случаях не подвергаются достаточно тщательному тестированию. Более того, в случае пользовательской реализации достижение максимальной производительности почти всегда приносится в жертву сокращению сроков разработки. В результате этого пользовательские варианты реализации оказываются, как правило, менее надежными и менее эффективными по сравнению с профессиональными решениями, предназначенными для широкого использования. Ввиду вышесказанного вам уже должно быть ясно, что для чтения и записи XML-данных гораздо лучше использовать библиотечные функции, специально разработанные для этой цели и прошедшие строгое тестирование. Преимущество этих функций заключается в том, что они проектировались, создавались и тестировались группой специалистов, способных с полным знанием дела справиться с задачей создания наиболее быстрого и надежного механизма для работы с XML. Для работы с XML-документами в .NET Compact Framework предлагается двухуровневый подход: ■ Средства однонаправленного чтения и записи XML-документов. Для максимально быстрого выполнения однонаправленного (forward-only) чтения/записи XML-документов без применения кэширования используются классы XmlReader и XmlWriter. Задачей этих классов является чтение или запись XML-данных соответственно из потоков или в потоки с поддержкой лишь минимально необходимого объема информации о состоянии. Этими возможностями могут воспользоваться разработчики, имеющие дело с XML-документами большого объема, когда на первый план выступает необходимость обеспечения высокой производительности приложений. ■ XML DOM (Document Object Model — объектная модель документов). Класс XmlDocument используется для представления создаваемого в памяти дерева объектов, описывающего XML-документ. XmlDocument и связанные с ним классы представляют объектную модель документов, обеспечивающую легкий доступ к элементам представляемых деревьев XML. Документ считывается только в прямом направлении с использованием обсуждавшегося выше класса XmlReader, на основании чего создается дерево элементов, представляющее XML-документ в памяти. Аналогичным образом, данные из XML-дерева могут быть записаны в поток; для выполнения этой задачи используется класс XmlReader. Возможности класса XmlDocument больше всего подходят тем разработчикам, которые либо имеют дело с XML-документами небольших или средних размеров, либо хотят вносить как можно меньше усложнений при работе с XML-документами Концептуально соответствующая функциональность концептуально представлена в пространстве имен System.Xml.*. Библиотеки данныхДанные в современных базах данных хранятся в виде наборов взаимосвязанных таблиц. Для работы с реляционными данными такого рода в NET Framework предлагается объектная модель под названием ADO.NET. Модель ADO.NET предоставляет в распоряжение разработчиков классы, позволяющие управлять в памяти набором связанных между собой реляционных таблиц, а также классы, обеспечивающие различные представления этих данных. О данных, для управления которыми используется модель ADO.NET, говорят, что они находятся в объекте DataSet. В чем состоит разница между ADO и ADO.NET? При работе с наборами данных DataSet, хранящимися в памяти, разработчики имеют возможность выполнять над ними целый ряд операций, включая следующие: ■ Сохранение внесенных текущих изменении в базах данных. Интерфейс между объектами ADO.NET DataSet и базами данных обеспечивается классом DataAdapter. Классы DataAdapter получают список добавлений, обновлений и удалений, относящийся к DataSet, и применяют соответствующую логику для распространения этих изменений на основную базу данных. Обычно это делается путем выполнения SQL-операторов или вызова хранимых процедур, предназначенных для работы с базой данных. ■ Сохранение данных в виде XML-документа. Объекты DataSet можно сериализовать в документы XML и сохранять в виде файлов с возможностью их последующей повторной загрузки. ■ Пересылка данных другому звену. Поскольку объекты DataSet, включая информацию о внесенных в них изменениях, без труда переводятся в форму постоянно существующих XML-документов, можно легко осуществлять их передачу между различными звеньями вычислительной системы посредством вызовов Web-служб. ■ Локальное использование данных. Объекты DataSet можно использовать как мощную абстракцию для работы с базами данных в памяти. Если эти данные предназначены только для чтения то внесенные в них локальные изменения не распространяются на данные, расположенные на сервере или в долговременном хранилище. Вынесение полезной отладочной и проектной информации в необязательные компонентыУправляемый код может содержать большое количество информации, которая может быть полезной для разработчиков при отладке каркасов, компонентов и приложений. В качестве примера подобных данных, привносящих добавленную стоимость, можно привести текстовые описания возможных исключений, которые возникают в процессе выполнения кода. Одно дело, когда сообщения об ошибках выводятся в виде малоинформативных фраз наподобие "Неизвестное исключение" или "Возбуждено исключение System.IO.SomeRandomException", и совершенно другое, когда вы получаете понятное простому смертному сообщение, подробно описывающее суть происшедшего и его наиболее вероятную причину. Информация подобного рода полезна на стадиях тестирования и отладки, но при разработке таких крупных проектов, как NET Compact Framework, для хранения всех строк сообщений об ошибках может потребоваться слишком много места, что в случае мобильных устройств является непозволительной роскошью. .NET Framework для настольных компьютеров просто включает в себя обширную информацию об исключениях наряду с другими ресурсами. Эта информация доступна не только на английском, но и на многих других основных языках, для которых была выполнена локализация Visual Studio; это означает, что конечные пользователи имеют возможность получать богатую диагностическую информацию на своем родном языке. Чтобы обеспечить доступ к этой информации программным путем, каждое исключение управляемого кода имеет свойство .Message, открывающее программный доступ к соответствующему тексту. Наличие текстовых строк с богатой отладочной информацией является несомненным преимуществом, однако за это преимущество приходится платить увеличением размера системы. Изначально ясно, что для подробных текстовых описаний требуется выделять много места. Для этого потребуется еще больше места, если предусмотрена локализация описаний. В связи с этим возникает вопрос о возможных проектных ограничениях, поскольку задачи обеспечения компактности системы и предоставления как можно более подробной текстовой информации вступают в конфликт между собой. В .NET Compact Framework эта проблема решается за счет разбиения указанной информации на отдельные вспомогательные компоненты не входящие в базовый состав NET Compact Framework. Эти вспомогательные компоненты могут устанавливаться поверх .NET Compact Framework в соответствии с необходимостью или желанием. Файл, содержащий эту информацию, имеет название System.SR.dll, а его размер составляет 91 Кбайт. Для других языков локализации предусмотрены дополнительные версии этого файла. Всего в настоящее время существует 10 таких локализованных языковых версий, суммарный размер которых достигает 900 Кбайт, что составляет ощутимую долю общего размера .NET Compact Framework. Таким образом, исключение этих строк из .NET Compact Framework позволяет значительно уменьшить суммарный размер системы. При установке .NET Compact Framework в ОЗУ или ПЗУ мобильных устройств указанные вспомогательные файлы, как правило, не устанавливаются; обычно их устанавливают лишь тогда, когда это необходимо или желательно. В среде разработки Visual Studio .NET эти файлы автоматически устанавливаются во время отладки, поскольку их присутствие почти всегда является желательным для разработчиков Если во время выполнения возбуждается исключение, .NET Compact Framework проверяет, присутствует ли на устройстве соответствующая языковая версия файла с диагностическими текстами исключений. Если это так, то осуществляется доступ к нужному файлу и загружается соответствующее текстовое описание. В противном случае NET Compact Framework пытается найти языково-инвариантную (английскую) версию ресурсного файла со строками описаний исключений. Если этот файл присутствует, выполняется загрузка текста. Если же файл отсутствует, отображается заданный по умолчанию текст, в котором ошибка не конкретизируется (хотя программное имя исключения и может дать некоторую информацию о ее природе). Использование механизма необязательных вспомогательных компонентов в .NET Compact Framework позволило достичь разумного баланса между максимально возможным уменьшением размера системы и предоставлением разработчикам как можно более полной отладочной информации Аналогичная стратегия проектирования применяется и в тех случаях, когда компоненты могут предоставить на стадии проектирования некую дополнительную информацию, которая не потребуется во время выполнения. В процессе создания пользовательских элементов управления можно создать отдельные версии компонентов для стадии проектирования и времени выполнения, различающиеся тем, что компоненты, используемые на стадии проектирования, содержат дополнительные метаданные, интерпретация которых на стадии разработки предоставляет расширенную информацию, позволяющую принимать более эффективные проектные решения Аналогичные модели, предусматривающие создание необязательных файлов ресурсов или отдельных версий компонентов для стадии проектирования, вы можете применять и в своей практике проектирования приложений, если это может привести к существенному уменьшению размера приложения. Средства подключения к базам данных SQL СЕ/SQLНеобязательные компоненты другой разновидности, которые могут устанавливаться поверх .NET Compact Framework, обеспечивают связь с определенными базами данных. Когда поставлялась версия 1.1 .NET Compact Framework, одновременно с ней поставлялись ее необязательные компоненты, обеспечивающие доступ к локальным базам данных SQL СЕ и удаленным базам данных SQL Server. Не являясь частью базового состава .NET Compact Framework, эти компоненты оказываются весьма полезными при создании приложений, работающих с упомянутыми базами данных. Существуют также аналогичные компоненты, обеспечивающие доступ к базам данных сторонних разработчиков. Элементы, отсутствующие в первой версии .NET Compact FrameworkЗащита доступаКонцепция явной проверки полномочий являлась центральной при проектировании общеязыковой среды выполнения (Common Language Runtime), лежащей в основе как .NET Framework, так и NET Compact Framework. Другим распространенным на званием этой концепции является безопасность доступа кода. Средства безопасности доступа кода обеспечивают возможность управления предварительно определяемыми политиками, разрешающими выполнение кода на основании подтверждений, предоставляемых самим кодом. Такими подтверждениями могут, например, служить криптографическая подпись, подтверждающая подлинность издателя компонента, полное имя самого компонента, местоположение установки компонента в локальной файловой системе или URL-адрес, с которого был загружен компонент. На основании предоставленного подтверждения и локальной политики, определенной для той машины, на которой должен выполняться код, коду предоставляются те или иные полномочия. В качестве примера можно привести следующие возможные уровни полномочий: ■ Полные доверительные отношения. Код выполняется в системе на уровне полных доверительных отношений и может делать все то, что могло бы делать собственное приложение. ■ Ограниченный доступ к файловой системе. Операции файлового ввода-вывода могут быть запрещены или ограничены некоторыми каталогами, исходя из подтверждений, предоставленных компонентом. ■ Ограниченный доступ к пользовательскому интерфейсу. Возможность вызова пользовательских интерфейсов может быть разрешена или запрещена компонентам. ■ Сетевой доступ. Возможность доступа к сети может быть разрешена или запрещена компонентам. ■ Доступ к собственному коду. Возможность осуществления вызовов собственных кодов может быть разрешена или запрещена компонентам. В варианте .NET Framework, ориентированном на настольные компьютеры и серверы, доступны не только эти, но и многие другие разрешения, которые могут определяться в качестве политик. По данному вопросу имеется обширная литература и документация. .NET Compact Framework проектировалась с учетом поддержки описанной модели безопасности, основанной на политиках. Однако в первом выпуске .NET Compact Framework политика безопасности определялась очень просто: "Весь код пользуется полными доверительными отношениями". Это означает, что приложения, предназначенные для .NET Compact Framework v1.1, выполняющейся на устройстве, будут выполняться в этой среде с тем же набором разрешений, с которым на устройстве выполняются собственные коды. Решение о закреплении разрешенных полномочий на уровне "выполнения в условиях полных доверительных отношений" для первого выпуска .NET Compact Framework было продиктовано исключительно прагматическими соображениями. В ходе обсуждений, сопровождавших ранние опыты внедрения данного продукта, стало очевидным, что первая волна конкурентоспособных приложений для мобильных устройств будет, скорее всего, представлена приложениями, которые явным образом устанавливаются на устройствах пользователями или администраторами, а не загружаются и выполняются на лету. Подобные виды приложений начали уже в заметной степени вытеснять традиционные приложения для устройств на основе собственных кодов, и поэтому использование аналогичной модели полномочий вполне соответствовало сложившейся ситуации. Если бы мы располагали неограниченным временем для проектирования, построения, тестирования и окончательного уточнения политик безопасности на основании откликов пользователей, то модель, используемая в первой версии, была бы проработана более тщательно. Однако в результате многочисленных дискуссий мы поняли, что не это требование будет определять успешность выполнения приложений в нашей первой версии продукта. В силу этого создание более совершенного механизма политик безопасности было отложено до следующего выпуска, что дало возможность сконцентрировать усилия на разработке других средств, вошедших в первую версию. Это решение далось нелегко, однако, по прошествии уже достаточно большого времени, мы по-прежнему убеждены в его правильности. Следует отметить, что на некоторых из устройств, пользующихся массовым спросом, например, на некоторых смартфонах, эксплуатируются политики безопасности, требующие, чтобы приложения, основанные на собственных кодах, были снабжены криптографическими подписями; в случае таких устройств в отношении приложений, основанных на управляемом коде, действуют те же политики. В дальнейшем желательно внедрить модель безопасности, поддерживающую загрузку кода на лету и присвоение полномочий на основе подтверждений, предоставляемых кодом. Поэтому весьма вероятно, что в будущих версиях .NET Compact Framework будет предусмотрено несколько различных уровней доверительности и полномочий, охватывающих интервал от "полного доверия" на основе предоставляемых подтверждений до весьма ограниченных возможностей для кода, пользующегося низким уровнем доверительности. Кроме того, различные типы мобильных устройств будут, вероятно, характеризоваться заданием на них различных политик. На некоторых устройствах политики будут определяться конечными пользователями, на других — администраторами, изготовителями оборудования или же сетевыми операторами, обслуживающими то или иное устройство. Поддержка этих возможностей будет осуществляться встроенной моделью обеспечения безопасности доступа. МультимедиаЕще одной областью, от явной поддержки которой в первом выпуске .NET Compact Framework мы решили отказаться, является работа с мультимедийной информацией. Это, например, означает, что разработчики, желающие воспроизводить звуки или показывать видео, должны использовать для этой цели собственные коды. Как и в предыдущем случае, если бы для разработки, тестирования и доработки этих средств у нас было больше времени, то их поддержка была бы обеспечена уже в первом выпуске .NET Compact Framework. Анализ отзывов, полученных нами от лиц, проводивших первые испытания этого продукта, позволил сделать вывод, что применительно к тем видам приложений, в создании которых в настоящее время существует потребность, поддержка данных возможностей не являлась критическим фактором успешности. По всей вероятности, в будущих версиях .NET Compact Framework поддержка мультимедийной информации будут более интенсивной. Оглядываясь назад, мы можем констатировать, что принятое нами решение было правильным. Как запускается и выполняется кодПри первоначальном запуске приложения на основе управляемого кода загрузка, верификация и запуск кода осуществляются за несколько шагов. Когда такое приложение уже запущено и выполняется, среда выполнения управляемого кода продолжает играть важную роль во время загрузки новых классов и JIT-компиляции кода, когда это оказывается необходимым, а также в процессе управления памятью, отводимой для приложения. Полезно иметь более или менее полное общее представление о том, как все это происходит. Процесс запуска и выполнения приложения можно пояснить при помощи описанных ниже шести шагов: 1. Загружается управляемое приложение. Двоичный заголовок приложения указывает операционной системе на то, что оно не является приложением в собственных кодах. Вместо того чтобы просто предоставить возможность выполняться инструкциям кода, загружается исполнительный механизм .NET Compact Framework, которому сообщается о том, что он должен запустить приложение на выполнение. 2. Исполнительный механизм находит класс, содержащий "главную" точку входа "main", с которой должно начинаться выполнение приложения. Таковым является класс с сигнатурой функции, соответствующей виду static void Main(). В случае обнаружения типа с такой сигнатурой происходит загрузка класса и производится попытка выполнения "главной" процедуры (шаги 3 и 4). 3. Загружается класс. Информация о классе загружается и верифицируется с той целью, чтобы убедиться в корректности и согласованности определения класса. Все методы (то есть точки входа исполняемого кода) класса обозначаются как "некомпилированные". 4. Исполнительный механизм пытается выполнить указанную процедуру. Если уже имеется откомпилированный код, связанный с процедурой, осуществляется выполнение этого кода. 5. Если исполнительный механизм обнаруживает, что свойство или метод, которые требуется запустить на выполнение, не откомпилированы, они компилируются по требованию. Производится загрузка содержащейся в классе информации, которая необходима методу. Код верифицируется для гарантии того, что он содержит безопасные, допустимые и корректно сформированные IL-инструкции, а затем подвергается JIT-компиляции. Если метод ссылается на другие типы, которые еще не были загружены, осуществляется необходимая загрузка определений соответствующих классов и типов. Методы, содержащиеся в классах, не компилируются до тех пор, пока в этом не возникнет необходимости; именно в этом и состоит смысл JIT-компиляции. 6. Выполняется скомпилированный к этому моменту метод. Если возникает необходимость в распределении памяти для типов или методов, исполнительному механизму направляются соответствующие запросы. Любые вызовы классов методами возвращают нас к шагу 5. На первый взгляд, вышеперечисленные действия требуют выполнения большого объема работы, однако в действительности все происходит очень быстро. Что такое "тип"? Управление памятью и сборка мусораВ процессе своего обычного выполнения ваш код периодически инициирует загрузку определений типов в память, компиляцию и выполнение кода, а также размещение объектов в памяти и их удаление из памяти. .NET Compact Framework проектировалась таким образом, чтобы обеспечить наилучший баланс между скоростью запуска, устойчивостью и непрерывностью выполнения кода даже в условиях существования жестких ограничений на объем доступной памяти. Для достижения этой цели загрузчик классов, механизм JIT-компиляции, а также модули распределения памяти и сборки мусора работают скоординированным образом. Вероятнее всего, выполнение вашего кода будет сопровождаться периодическим созданием новых объектов и их последующим уничтожением после того, как необходимость в них исчезает. Эффективное удовлетворение запросов памяти для размещения объектов и ее освобождение достигаются в .NET Compact Framework за счет утилизации освобождаемой памяти путем так называемой "сборки мусора" (garbage collection). Операции по сборке мусора в той или иной форме используются в большинстве современных сред выполнения управляемого кода. Сборка мусора в основном предназначена для решения двух задач: 1) восстановления памяти, которая больше не используется, и 2) уплотнения участков используемой памяти таким образом, чтобы для вновь распределяемых областей памяти были доступны как можно более крупные блоки. Тем самым решается одна из наиболее распространенных проблем, которая называется фрагментацией памяти. По своей сути эта проблема аналогична проблеме фрагментации дискового пространства. Если дисковое пространство периодически не реорганизовывать, то по прошествии некоторого времени оно дезорганизуется и разобьется на ряд чередующихся свободных и занятых участков небольшого размера; эти участки и являются фрагментами. Можно считать, что здесь мы имеем дело с проявлением действия закона увеличения энтропии применительно к дисковому пространству и памяти; для того, чтобы обратить энтропийные эффекты, необходимо затратить определенную работу. В результате фрагментации доступ к данным замедляется, поскольку в процессе чтения файлов головкам приходится многократно перемещаться вдоль поверхности диска. Фрагментация памяти оборачивается еще худшими бедами, так как для размещения объектов требуются достаточно большие непрерывные блоки памяти, способные уместить целиком все данные, относящиеся к объекту. После выполнения многочисленных операций выделения и освобождения порций памяти различного размера свободные области оказываются расположенными вразброс, а их размеры являются недостаточными, чтобы обеспечивалось наличие больших непрерывных участков памяти, необходимых для размещения объектов. Уплотнение всей используемой, но расположенной вразброс памяти позволяет создавать крупные блоки свободной памяти, которую можно эффективно использовать при распределении памяти для вновь создаваемых объектов. Восстановление памяти является сравнительно несложным процессом. Выполнение кода временно прекращается, а активные (live) объекты (то есть объекты, к которым ваш код может осуществлять непосредственный или косвенный доступ) отыскиваются и рекурсивно помечаются. Так как остальные объекты, находящиеся в памяти, уже недоступны активному коду, они остаются непомеченными, что позволяет идентифицировать их как "мусор" и восстановить соответствующую память. Такая разновидность сборки мусора известна под названием "отслеживание и очистка" ("mark and sweep"). Обычно эта операция осуществляется довольно быстро. Возможность уплотнения объектов в памяти является дополнительным преимуществом выполнения управляемого кода. В этом случае, в отличие от собственных кодов, все известные ссылки на ваши объекты известны и исполнительному механизму. Благодаря этому можно перемещать объекты из одного места памяти в другое, если в этом возникает потребность. Диспетчер памяти (исполнительный механизм) отслеживает, где именно находятся те или иные объекты, и перемещает их в случае необходимости. Это позволяет уплотнять расположение набора управляемых объектов, разбросанных в памяти. Однако в рукаве у .NET Compact Framework наряду с JIT-компилятором, диспетчером памяти и сборщиком мусора спрятан еще один козырь: возможность очищать память от пассивного (dead) JIT-компилированного кода. Обычно это делать нежелательно, но при определенных обстоятельствах такая возможность становится незаменимой. Если уж исполнительный механизм, обеспечивая максимальную производительность, потрудился и выполнил JIT-компиляцию управляемого кода до собственных команд процессора, то отбрасывание JIT-компилированного кода могло бы показаться расточительством, поскольку когда в следующий раз возникнет необходимость в выполнении этого кода, то потребуется его повторная JIT-компиляция. В то же время, наличие такой возможности оборачивается благом в следующих двух случаях: 1. Когда приложение осуществило JIT-компиляцию и был выполнен большой объем кода, который в ближайшее время не будет вновь выполняться. Довольно часто ситуации подобного рода возникают в тех случаях, когда выполнение приложения происходит в несколько стадий. Вполне возможно, что код, запускаемый на начальной стадии выполнения приложения для инициализации или настройки объектов и данных, впоследствии повторно выполняться не будет. Если возникает необходимость в дополнительном распределении памяти, то имеется полный смысл использовать для этого память, в которой хранится данный код. 2. Когда набор хранящихся в памяти активных объектов становится настолько большим, что возникает риск аварийного завершения выполнения приложения, если для размещения дополнительных объектов, которые в соответствии с алгоритмом должны создаваться в ходе нормального выполнения приложения, не найдется достаточно большого объема свободной памяти. В этом случае исполнительный механизм будет вынужден вытеснять из памяти и периодически перекомпилировать необходимый приложению код лишь для того, чтобы приложение было в состоянии продолжать дальнейшее выполнение. Если другой возможной альтернативой является только прекращение выполнения приложения из-за нехватки памяти, то единственным решением может быть лишь очистка памяти от JIT-компилированного кода, даже если это означает дополнительные затраты времени на последующую повторную компиляцию этого кода. Краткий обзор методов управления памятью и сборки мусораПолезно разобраться в том, каким образом исполнительный механизм взаимодействует с кодом и объектами приложения в процессе его выполнения. Приведенные ниже схематические диаграммы помогут нам проследить, как осуществляется управление памятью на различных стадиях выполнения приложения. 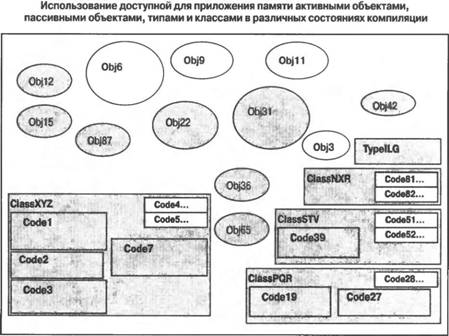 Рис. 3.2. Упрощенное схематическое представление состояния памяти приложения в процессе выполнения Таблица 3.1. Условные графические обозначения, используемые на рис. 3.2, 3.3 и остальных рисунках
Приведенную на рис. 3.2 схему можно прокомментировать следующим образом: ■ Размеры отдельных элементов схемы выбраны таким образом, чтобы они давали представление об относительных объемах используемой памяти. Визуально большие классы и типы используют больше памяти по сравнению с визуально меньшими, поскольку содержат больше "начинки". Объекты различных типов используют различные объемы памяти. Пассивные объекты занимают память до тех пор, пока не будет выполнена операция сборки мусора. Методы, не подвергавшиеся JIТ-компиляции, занимают в памяти очень мало места. ■ В память загружаются описания всех типов и классов, которые используются в вашем приложении. Для различных типов и классов требуются различные объемы памяти. ■ JIT-компиляции подвергаются методы класса, которые вызывались хотя бы один раз. Пример: JIT-компиляции подвергались коды Code1, Code2, Code3 и Code7 класса ClassXYZ. ■ Те методы классов, которые еще не вызывались, не компилируются и поэтому не занимают много места в памяти. Пример: методы Code4 и Code5 класса XYZ еще не подвергались JIТ-компиляции. Как только они будут вызваны, будет осуществлена их JIT-компиляция и произведено распределение памяти для откомпилированного кода. ■ Объекты представляют собой экземпляры типов и классов и требуют места в памяти. ■ "Активные (live) объекты" — это объекты, к которым ваш код может получить доступ путем непосредственного или опосредованного использования глобальных, статических и стековых переменных. ■ "Пассивные (dead) объекты" — это объекты, доступ к которым со стороны вашего приложения стал уже невозможным, но которые еще не были удалены из памяти исполнительным механизмом. Таковыми на рис. 3.2 являются объекты Obj 3, Obj 6, Obj 9 и Obj11. До тех пор пока эти объекты не будут удалены, они будут занимать память подобно активным объектам или JIT-компилированному коду. По мере того как объекты и другие типы, для которых память распределяется из кучи, будут создаваться вашим приложением и впоследствии становиться ненужными, наступит такой момент, когда невозможно будет создать никакой другой дополнительный объект, не удалив из памяти пассивные объекты. Как только это произойдет, исполнительный механизм инициирует сборку мусора. Состояние памяти приложения непосредственно перед выполнением операции сборки мусора показано на рис. 3.3. По окончании сборки мусора становится возможным уплотнение активных объектов в памяти. Удаление пассивных объектов из памяти с последующим уплотнением активных объектов во многих случаях позволяет сформировать непрерывные свободные участки памяти большого размера, которые могут быть использованы при создании новых объектов. Состояние памяти приложения непосредственно после выполнения операций сборки мусора и уплотнения объектов показано на рис. 3.4. 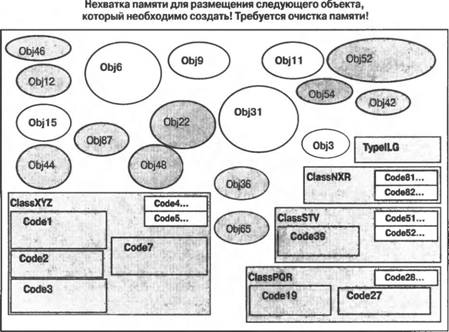 Рис. 3.3. Состояние памяти приложения непосредственно перед сборкой мусора 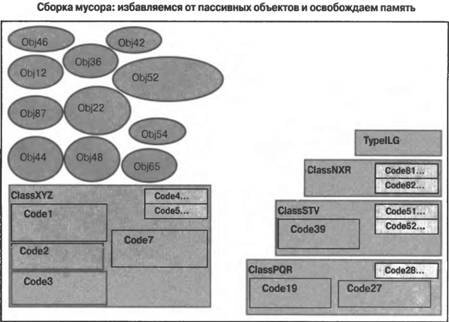 Рис. 3.4. Пассивные объекты удалены из памяти, а активные — уплотнены В состоянии нормального устойчивого выполнения приложение периодически создает объекты и избавляется от них. В необходимых случаях исполнительный механизм осуществляет сборку мусора и уплотняет память, освобождая ее для размещения вновь создаваемых объектов. Типичное состояние памяти приложения в условиях сосуществования активных и пассивных объектов, а также JIT-компилированного и некомпилированного кода показано на рис. 3.5. В случае нормально функционирующих приложений всегда имеется запас свободной памяти, достаточный для создания новых объектов и хранения ненужных, так что прибегать к сборке мусора приходится сравнительно редко. Объема областей памяти, освобождаемых в процессе сборки мусора, надолго хватает для того, чтобы приложение могло создавать новые объекты, не заботясь об удалении тех, необходимости в которых больше нет. Типичное состояние памяти приложения непосредственно после выполнения очередной операции сборки мусора представлено на рис. 3.6. Иногда количество используемых активных объектов может возрастать настолько, что простое удаление пассивных объектов по типу "отслеживание и очистка" не может обеспечить освобождение достаточно большого объема памяти для того, чтобы исполнительный механизм мог создать и разместить в памяти новые объекты, которые требуются выполняющемуся коду приложения. В случае возникновения подобных ситуаций выполнение приложения должно быть прекращено из-за нехватки памяти. Состояние приложения, достигшего в ходе своего выполнения такого состояния, показано на рис. 3.7. 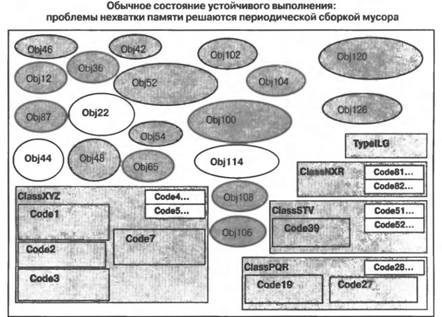 Рис. 3.5. Типичное состояние памяти приложения при его устойчивом выполнении 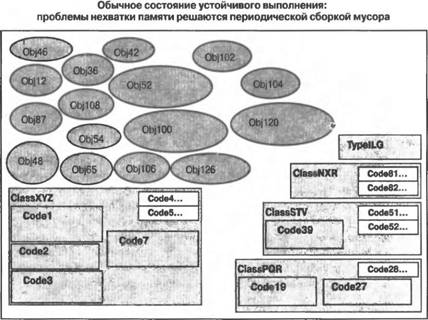 Рис. 3.6. Типичное состояние памяти приложения при его устойчивом выполнении непосредственно после сборки мусора 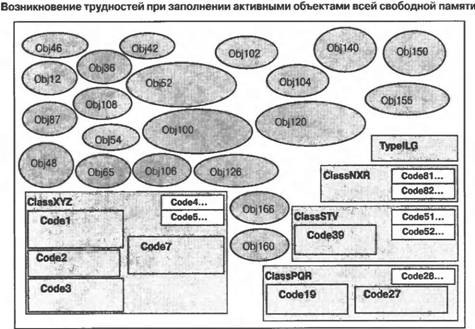 Рис. 3.7. Активные объекты, занимающие всю доступную память .NET Compact Framework справляется с подобными ситуациями, освобождая большие количества памяти, занимаемой текущим JIT-компилированным кодом. Может быть сброшен любой код, не выполняющийся в данный момент с использованием стека (или стеков, если речь идет о многопоточном выполнении). Это позволяет востребовать обратно память и использовать ее для нужд приложения, связанных с необходимостью размещения новых объектов или JIT-компиляции нового кода в случае, если метод ранее не выполнялся, но теперь вызывается. Состояние памяти приложения после отбрасывания ранее JIT-компилированного кода и сборки мусора показано на рис. 3.8. Удаление JIT-компилированного кода является серьезным шагом, ибо часть этого кода придется JIT-компилировать повторно, но эта мера может оказаться весьма эффективной, если значительная часть ранее JIT-компилированного кода больше не потребуется для выполнения приложения. Это часто имеет место в тех случаях, когда заметная доля кода приходится на "начальный" код, используемый лишь для настройки последующего выполнения, или когда приложение разделяется на логические блоки, которые не обязательно должны выполняться все одновременно. Состояние памяти приложения вскоре после того, как отброшен весь возможный JIT-компилированный код, показано на рис. 3.9. Последующее размещение новых объектов и повторная JIT-компиляция кода методов осуществляются по мере необходимости. 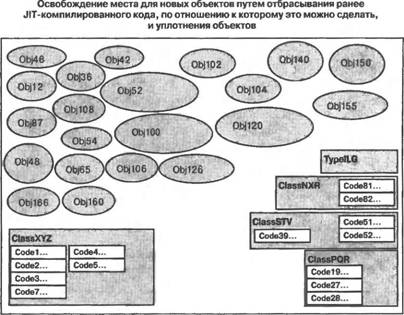 Рис. 3.8. Удаление ранее JIT-компилированного кода и освобождение памяти, которая ранее была занята JIT-компилированным кодом методов 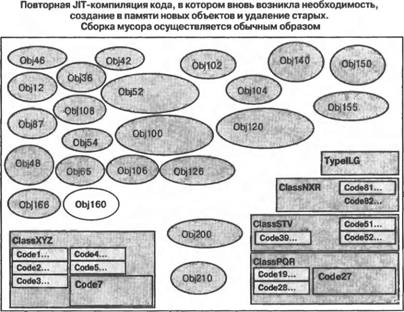 Рис. 3.9. Методы подвергаются повторной JIT-компиляции по мере их вызова, новые объекты размещаются в памяти, а отбрасываемые объекты становятся "мусором" Производительность может резко снизиться, если приложение продолжает размещать в памяти все новые и новые объекты, не освобождая ее от старых. Такая ситуация будет приводить к возникновению условий, при которых единственное, что удается удерживать в памяти, — это активные объекты и код, непосредственно указанные в стеке приложения (или стеках, если речь идет о многопоточном выполнении). В этом случае обычный код должен непрерывно подвергаться JIT-компиляции и освобождать память, когда необходимость в нем отпадает, поскольку для хранения JIT- компилированного кода доступна лишь небольшая часть памяти системы. Таким образом, системе приходится выполнять много лишней работы, то есть она, как принято говорить, "молотит впустую", поскольку и приложение, и среда времени выполнения работают на полную мощность с низкой эффективностью лишь для того, чтобы поддерживать возможность выполнения кода небольшими порциями. По мере асимптотического приближения приложения к этому состоянию его производительность резко падает. Возникновения таких состояний следует избегать! Пример приложения, оказавшегося в подобном состоянии, проиллюстрирован на рис. 3.10. 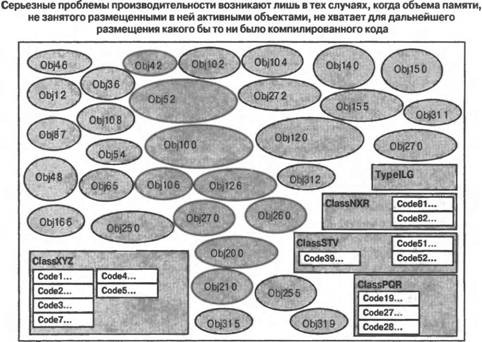 Рис. 3.10. Чрезмерно интенсивная загрузка памяти. Активные объекты занимают всю доступную память даже после того, как она максимально освобождена от JIT-компилированного кода Резюме.NET Compact Framework представляет собой богатую своими возможностями среду времени выполнения управляемого кода для мобильных устройств, пригодную для создания самых различных приложений, компонентов и каркасов приложений. Она с самого начала предназначалась для использования на устройствах, характеризующихся ограниченными ресурсами, но с самого начала проектировалась как совместимое на уровне двоичного кода подмножество платформы .NET Framework, ориентированной на настольные компьютеры и серверы. Подобно другим средам выполнения управляемого кода .NET Compact Framework включает в себя механизм выполнения собственных кодов и набор библиотек классов выполняющегося поверх него управляемого кода. Были применены стратегии проектирования, специально предназначенные для мобильных и встроенных устройств, что позволило обеспечить предоставление широкого подмножества функциональности платформы NET Framework и одновременно учесть специфику требований мобильных устройств в отношении размеров и производительности приложений. Библиотеки классов, поставляемые в составе .NET Compact Framework версии 1.1, могут быть условно разбиты на пять логических блоков: 1) пользовательский интерфейс и поддержка графики, 2) поддержка XML, 3) поддержка клиентов Web-служб, 4) поддержка доступа к данным и всей связанной с этим функциональности, и 5) библиотеки базовых классов. Библиотеки базовых классов проектировались таким образом, чтобы разработчики приложений для настольных компьютеров чувствовали себя комфортно и уверенно при написании кодов для устройств; они должны найти здесь все средства, наличие которых могли ожидать. Сочетание указанных библиотек предоставляет разработчикам богатую палитру функциональных возможностей, которые позволяют создавать приложения коммерческого, производственного, научного и развлекательного характера. По всей видимости, в будущих версиях .NET Compact Framework будет добавлена поддержка моделей, обеспечивающих безопасность доступа кода, а также поддержка мультимедийных средств. При создании приложений, предназначенных для выполнения в управляемых средах, особенно на мобильных устройствах, полезно иметь общее концептуальное представление о том, каким образом в таких средах осуществляется управление памятью и выполнением приложения. В .NET Compact Framework предлагается JIT-компиляция кода, а также освобождение памяти, используемой приложением, от "мусора". При нормальном выполнении приложения в очистке от "мусора" и периодическом уплотнении нуждается лишь память, занимаемая объектами. Если же необходимость в свободном пространстве возникает в условиях интенсивной загрузки памяти, то операции освобождения памяти и сборки мусора могут применяться также по отношению к JIT-компилированному коду. Аналогично тому, как в случае приложений, основанных на собственных кодах, возможно исчерпание памяти, серьезные проблемы, связанные с перерасходом памяти, могут возникать и в управляемых средах. Это происходит тогда, когда приложение исчерпывает всю доступную память в процессе размещения объектов. В подобных случаях производительность приложения резко падает, поскольку сборщик мусора постоянно пытается освобождать для вновь возникающих нужд память, острая нехватка которой становится все ощутимее. Если необходимую память распределить не удается, приложение завершается аварийно. Ситуаций, в которых возникает острая нехватка памяти, следует избегать, и в последующих главах книги значительная доля внимания будет уделена обсуждению того, как проектировать алгоритмы и создавать приложения, способные эффективно работать с такими ресурсами устройств, как память, освобождаемая в результате сборки мусора. Такие среды времени выполнения управляемого кода, как .NET Compact Framework, предоставляют разработчикам большие преимущества при создании приложений для мобильных устройств. Производительность и надежность управляемых сред времени выполнения, а также богатые библиотеки классов и компоненты, обеспечивающие повторное использование кода, никого не оставят равнодушным. Однако чтобы в полной мере воспользоваться всеми достижениями, реализованные в рамках платформы для мобильных приложений, разработчики должны хорошо понимать на концептуальном уровне, каким образом осуществляется управление памятью и выполнением приложений. Владение этими знаниями в сочетании с учетом специфики устройств позволит вам после приобретения соответствующих технических навыков создавать замечательные мобильные приложения. |
|
||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||||||||||||||
|
|
||||||||||||||||